Funkcja przejścia filtru dolnoprzepustowego 1 stopnia dana ogólnie
$H(s) = \displaystyle\frac{1}{s R C + 1}$
Korzystając z informacji w http://en.wikipedia.org/wiki/Low-pass_filter równanie różnicowe takiego filtra możemy zapisać jako:
$y(n) = b_0x(n) + b_1x(n-1) + b_2x(n-2) - a_1y(n-1) - a_2y(n-2)$
, gdzie:
$b_0 = \displaystyle\frac{T}{RC+T}$
$b_1 = 0$
$b_2 = 0$
$a_1 = b_0 - 1$
$a_2 = 0$
Jeśli skorzystamy tutaj z metody takiej jak przy filtrze drugiego stopnia to nasze wynikowe blepy będą się nieznacznie różnić. Maksymalny błąd względny będzie rzędu 0.001. Podana tutaj wyżej metoda jest pozbawiona tego błędu.
Istnieje wiele metod konwersji filtrów ciągłych w czasie na dyskretne. W zależności od charakterystyki funkcji H(s) metody te mogą dawać mniej lub bardziej dokładną postać H(z).
Kolejna uwaga: porównując wersję lsim do wersji bq widzimy, że powyższa metoda nie generuje takich samych wyników jak lsim. Takie same wyniki jak lsim generuje metoda taka jak dla drugiego rzędu. Jeśli uznać, że lsim jest najdokładniejszy, zaś metody różnicowe są mniej dokładne to metoda z filtru drugiego stopnia jest dokładniejsza. Czemu więc w WinUAE zastosowano metodę mniej dokładną.
Porównując charakterystykę częstotliwością sygnału lsim z bq wygenerowanym przez metodę taką jak dla filtra drugiego rzędu widzimy, że choć różnice w czasie są znaczne (0.001), różnice w częstotliwości są znacznie mniejsze (0.0001).
Kolejna uwaga: oryginalny kod w pythonie wykorzystuje tak zwane frequency prewarping, brak tego w kodzie C# powoduje błąd rzędu $10^{-5}$. Przy czym nie wiem czy ten błąd jest spowodowany głównie brakiem FQ PW. Tak więc wydaje się, że stosowanie tej techniki mija się tutaj z celem.
2012-05-01
Window function - Kaiser w Python
Tutaj implementacja w Python z wykorzystaniem odwołania do scipy.special.iv, czyli Modified Bessel function of first order. Mam nadzieję, że w następnym poście podam kod na scipy.special.iv. Wtedy wszystko będzie już gotowe do przeniesienia w C#. By tam generować BLEP-y programowo jakie się nam wymarzy.
def kaiser(samples, beta): result = [0] * samples M = samples - 1 for i in range(samples): num = special.iv(1, beta*math.sqrt(1-(2*i/M - 1)**2)) den = special.iv(1, beta) result[i] = num / den return result
2012-04-30
Transformata Z i równanie różnicowe filtru dolnoprzepustowego drugiego stopnia
Filtr dolnoprzepustowy pierwszego stopnia zostanie omówiony w innym poście. Nie możemy użyć poniższych wzorów podstawiając po prostu A=0. Ale za to podstawienie A=0 i B=0 daje poprawne wyniki.
Filtru dolnoprzepustowego drugiego stopnia:
$H(s) = \displaystyle\frac{1}{s^2 R_1 R_2 C_1 C_2 + s(R_1 C_1 + R_2 C_2) + 1}$
Ogólnie:
$H(s) = \displaystyle\frac{1}{s^2 A + s B + 1}$
Filtr pierwszego stopnia to filtr dla którego A = 0.
Korzystając z wzoru na związek pomiędzy transformatą Laplaca a Z:
$s =\displaystyle\frac{2}{T} \frac{(z-1)}{(z+1)}$
Po przekształceniach otrzymujemy:
$H(z) = \displaystyle\frac{T^2 + 2T^2z^{-1} + T^2 z^{-2}}{4A+2TB+T^2 + (2T^2-8A)z^{-1}+(4A-2TB+T^2)z^{-2}}$
Co możemy zapisać jako:
$H(z)=\displaystyle\frac{b_0+b_1z^{-1}+b_2z^{-2}} {1+a_1z^{-1}+a_2z^{-2} }$
, gdzie:
$a_0=4A+2TB+T^2$
$a_1=(2T^2-8A)/{a_0}$
$a_2=(4A-2TB+T^2)/{a_0}$
$b_0={T^2}/{a_0}$
$b_1={2T^2}/{a_0}$
$b_2={T^2}/{a_0}$
T to okres co jaki chcemy otrzymywać kolejne próbki, w naszym przypadku jest to częstotliwość z jakiej wielokrotnością custom chip jest w stanie zmieniać wyjście.
Filtr zapisany w takiej postaci to Digital biquad filter.
Takie funkcji przejścia odpowiada następujące równianie różnicowe:
$y(n) = b_0x(n) + b_1x(n-1) + b_2x(n-2) - a_1y(n-1) - a_2y(n-2)$
Wszystko to pozwala nam na generowania przebiegów BLEP wprost z równania różnicowego, którego parametry są bezpośrednio określone parametrami elektrycznymi filtra i częstotliwością z jaką chcemy ciągły sygnał próbkować.
Filtru dolnoprzepustowego drugiego stopnia:
$H(s) = \displaystyle\frac{1}{s^2 R_1 R_2 C_1 C_2 + s(R_1 C_1 + R_2 C_2) + 1}$
Ogólnie:
$H(s) = \displaystyle\frac{1}{s^2 A + s B + 1}$
Filtr pierwszego stopnia to filtr dla którego A = 0.
Korzystając z wzoru na związek pomiędzy transformatą Laplaca a Z:
$s =\displaystyle\frac{2}{T} \frac{(z-1)}{(z+1)}$
Po przekształceniach otrzymujemy:
$H(z) = \displaystyle\frac{T^2 + 2T^2z^{-1} + T^2 z^{-2}}{4A+2TB+T^2 + (2T^2-8A)z^{-1}+(4A-2TB+T^2)z^{-2}}$
Co możemy zapisać jako:
$H(z)=\displaystyle\frac{b_0+b_1z^{-1}+b_2z^{-2}} {1+a_1z^{-1}+a_2z^{-2} }$
, gdzie:
$a_0=4A+2TB+T^2$
$a_1=(2T^2-8A)/{a_0}$
$a_2=(4A-2TB+T^2)/{a_0}$
$b_0={T^2}/{a_0}$
$b_1={2T^2}/{a_0}$
$b_2={T^2}/{a_0}$
T to okres co jaki chcemy otrzymywać kolejne próbki, w naszym przypadku jest to częstotliwość z jakiej wielokrotnością custom chip jest w stanie zmieniać wyjście.
Filtr zapisany w takiej postaci to Digital biquad filter.
Takie funkcji przejścia odpowiada następujące równianie różnicowe:
$y(n) = b_0x(n) + b_1x(n-1) + b_2x(n-2) - a_1y(n-1) - a_2y(n-2)$
Wszystko to pozwala nam na generowania przebiegów BLEP wprost z równania różnicowego, którego parametry są bezpośrednio określone parametrami elektrycznymi filtra i częstotliwością z jaką chcemy ciągły sygnał próbkować.
2012-04-20
Konwersja repozytorium SVN Codeplex na Mercurial
Ciąg dalszy zabawy. Wszelkie polecenia i rozszerzenia (hgsubversion, svn dump, svnrdump, hg convert) zawiodły. Pozostało napisanie kodu który ręcznie wyciąga dane z SVN rewizja po rewizji, kopiuje do katalogu repozytorium HG i zatwierdza z odpowiednim użytkownikiem, datą, komentarzem.
Pierwszy problem to kodowanie znaków. Moja aplikacja to konsola napisana w C#. Kodowanie znaków w konsoli to jakiś dos-owy standard. Polecenie svn log wywołane bezpośrednio z przekierowaniem strumienia do pliku zakoduje go w windows-1252, jeśli wywołam je z kodu to otrzymam strumień UTF-8, gdyż takie kodowanie ustawiłem dla strumieni output i error wywoływanego procesu.
Rozpoznawanie jak plik jest zakodowany nie ma sensu i jest bardzo trudne. Tak więc najlepiej zachować tutaj dyscyplinę.
Poza tym polecenie svn log wywoływane z kodu bardzo często kończy się błędem - za często. Tak więc wywołuje je osobno z svnlog.cmd na początku klikając w ten plik dwa razy.
Polecenie svn log potrafi zwrócić xml, w przypadku Codeplex nie zawiera on nic więcej informacji. a powinien. Atrybut kind powinien nam powiedzieć czy mamy do czynienia z plikiem czy z katalogiem. Taka informacja bardzo uprościła by mi pracę.
Co do wiarygodności svn log. Nie możemy ufać zawartym tam informacją. Po pierwsze są ewidentne błędy - svn log twierdzi, że coś się zmieniło, ale update nie i na odwrót. I nieścisłości. Dodajemy katalog z plikiem, ale svn log twierdzi, że zmodyfikowaliśmy lub dodaliśmy tylko plik. Bardzo często zmiany nazwy pliku i przeniesienie go w inne miejsce jest oznaczana za pomocą modyfikacji nowego pliku, a powinna być para A/D. SVN nie obsługuje zmiany nazwy pliku. Już nie mówiąc o tym, że pliki te różnią się.
No i jeszcze jeden kwiatek: zarówno svn log jak i update, potrafi zwrócić informację typu:
Części w nawiasach pozbywam się z wyrażeniem regularnym. Mojego testowego serwera nie udało mi się zmusić do wygenerowania takiej informacji. A oznacza ona, z tego co mi się wydaje, że plik został usunięty i ponownie dodany.
Po wykonaniu update, muszę zamienić ścieżki bezwzględne na względne, slashe na backslashe, dodać backslashe na początek, zamienić U na M. I najważniejsze, w przypadku kasowania katalogu svn log podaje pliki i katalog, update tylko katalog.
Później porównuje stan svn log z update i decyduję o tym, czy potrzebny jest pełny checkout.
Ostatecznie mam stan SVN na daną rewizję. Kasuje zawartość HG, kopiuje tam dane z SVN.
I wykonuje polecenie hg status by zobaczyć co się zmieniło. Konfrontuje je z svn log. Jak dotąd wszystkie błędy tutaj pokazywane są także wykazywane wcześniej na etapie update. HG w przeciwieństwie do SVN nie zarządza katalogami. Udało mi się wyeliminować tutaj wszelkie raportowane różnice. Pozostała tylko jedna. Kasowany pusty katalog w SVN. Skasowanie takiego katalogu po stronie HG nic nie znaczy, gdyż został on niejako usunięty z repozytorium wraz z ostatnim plikiem. Raportuje tutaj błąd by uniknąć false negative. Żadne błędy na tym etapie nie wywołują powrotu do checkout.
Zatwierdzam zmiany do HG. Kopiuje zawartość HG z powrotem do SVN i przechodzę do następnej rewizji.
Odpukać, jeszcze nie pobrałem wszystkich rewizji. Nie wiem czy się uda, czy nie będzie nowych błędów, czy nie będę musiał jakoś znacząco rozbudować kodu.
Jak je pobiorę to pozostanie etap, w którym będę starał się pobrać wszystkie rewizje za pomocą checkout i porównać pliki binarnie z rewizją w HG. Cały proces będzie się starał wybierać zawsze rewizję środkową w największej dziurze, czyli zawsze checkouty będą równo rozmieszczone. Rewizji mam jakieś 600, tak więc po zrobieniu z 60 checkoutów powinienem chyba być spokojny o spójność danych.
Na końcu i to już ręcznie postaram się wybrać rewizje w HG wokół, których działy się dziwne rzeczy, i skompilować dla nich kod. I ocenić ewentualne błędy kompilacji.
Pierwszy problem to kodowanie znaków. Moja aplikacja to konsola napisana w C#. Kodowanie znaków w konsoli to jakiś dos-owy standard. Polecenie svn log wywołane bezpośrednio z przekierowaniem strumienia do pliku zakoduje go w windows-1252, jeśli wywołam je z kodu to otrzymam strumień UTF-8, gdyż takie kodowanie ustawiłem dla strumieni output i error wywoływanego procesu.
Rozpoznawanie jak plik jest zakodowany nie ma sensu i jest bardzo trudne. Tak więc najlepiej zachować tutaj dyscyplinę.
Poza tym polecenie svn log wywoływane z kodu bardzo często kończy się błędem - za często. Tak więc wywołuje je osobno z svnlog.cmd na początku klikając w ten plik dwa razy.
Polecenie svn log potrafi zwrócić xml, w przypadku Codeplex nie zawiera on nic więcej informacji. a powinien. Atrybut kind powinien nam powiedzieć czy mamy do czynienia z plikiem czy z katalogiem. Taka informacja bardzo uprościła by mi pracę.
Co do wiarygodności svn log. Nie możemy ufać zawartym tam informacją. Po pierwsze są ewidentne błędy - svn log twierdzi, że coś się zmieniło, ale update nie i na odwrót. I nieścisłości. Dodajemy katalog z plikiem, ale svn log twierdzi, że zmodyfikowaliśmy lub dodaliśmy tylko plik. Bardzo często zmiany nazwy pliku i przeniesienie go w inne miejsce jest oznaczana za pomocą modyfikacji nowego pliku, a powinna być para A/D. SVN nie obsługuje zmiany nazwy pliku. Już nie mówiąc o tym, że pliki te różnią się.
No i jeszcze jeden kwiatek: zarówno svn log jak i update, potrafi zwrócić informację typu:
A /amiemu_lib/Savest/CPUState.cs (from /amiemu_lib/Savestate/CPUState.cs:82577)
Części w nawiasach pozbywam się z wyrażeniem regularnym. Mojego testowego serwera nie udało mi się zmusić do wygenerowania takiej informacji. A oznacza ona, z tego co mi się wydaje, że plik został usunięty i ponownie dodany.
Po wykonaniu update, muszę zamienić ścieżki bezwzględne na względne, slashe na backslashe, dodać backslashe na początek, zamienić U na M. I najważniejsze, w przypadku kasowania katalogu svn log podaje pliki i katalog, update tylko katalog.
Później porównuje stan svn log z update i decyduję o tym, czy potrzebny jest pełny checkout.
Ostatecznie mam stan SVN na daną rewizję. Kasuje zawartość HG, kopiuje tam dane z SVN.
I wykonuje polecenie hg status by zobaczyć co się zmieniło. Konfrontuje je z svn log. Jak dotąd wszystkie błędy tutaj pokazywane są także wykazywane wcześniej na etapie update. HG w przeciwieństwie do SVN nie zarządza katalogami. Udało mi się wyeliminować tutaj wszelkie raportowane różnice. Pozostała tylko jedna. Kasowany pusty katalog w SVN. Skasowanie takiego katalogu po stronie HG nic nie znaczy, gdyż został on niejako usunięty z repozytorium wraz z ostatnim plikiem. Raportuje tutaj błąd by uniknąć false negative. Żadne błędy na tym etapie nie wywołują powrotu do checkout.
Zatwierdzam zmiany do HG. Kopiuje zawartość HG z powrotem do SVN i przechodzę do następnej rewizji.
Odpukać, jeszcze nie pobrałem wszystkich rewizji. Nie wiem czy się uda, czy nie będzie nowych błędów, czy nie będę musiał jakoś znacząco rozbudować kodu.
Jak je pobiorę to pozostanie etap, w którym będę starał się pobrać wszystkie rewizje za pomocą checkout i porównać pliki binarnie z rewizją w HG. Cały proces będzie się starał wybierać zawsze rewizję środkową w największej dziurze, czyli zawsze checkouty będą równo rozmieszczone. Rewizji mam jakieś 600, tak więc po zrobieniu z 60 checkoutów powinienem chyba być spokojny o spójność danych.
Na końcu i to już ręcznie postaram się wybrać rewizje w HG wokół, których działy się dziwne rzeczy, i skompilować dla nich kod. I ocenić ewentualne błędy kompilacji.
2012-04-12
Rekonstrukcja dźwięku - notatki
Jak jest rozdzielczość DACa w Pauli. Wydaje się, że nawet jak na ówczesne czasy 14 bitów nie było poza ich zasięgiem, ale czy tak jest w rzeczywistości. Jak skalowane jest 8-bitów z sampla + 6-bitów z głośności.
Czy na A1200 której chipy są dwa razy szybsze Paula jest w stanie częściej zmieniać stan wyjścia DACa. To samo tyczy się A500. Istnieje tryb w którym CPU, nie DMA wypełnia rejestry dźwiękowe Pauli.
Na sztywno założyłem, że częstotliwość próbkowania hosta to 44100. Sam AudioReconstructor może pracować z dowolną. Tylko, że dla każdej takiej częstotliwości trzeba przygotować osobne BLEPy.
Czy na A1200 której chipy są dwa razy szybsze Paula jest w stanie częściej zmieniać stan wyjścia DACa. To samo tyczy się A500. Istnieje tryb w którym CPU, nie DMA wypełnia rejestry dźwiękowe Pauli.
Na sztywno założyłem, że częstotliwość próbkowania hosta to 44100. Sam AudioReconstructor może pracować z dowolną. Tylko, że dla każdej takiej częstotliwości trzeba przygotować osobne BLEPy.
hgsubversion
Nigdy więcej korzystania z czegoś takiego jakSVN na CodePlex. Tak naprawdę CodePlex nie wspiera SVN, natywnie dane są przechowywane w jakimś standardzie Microsoftu, i istnieje swego rodzaju pośrednik SVN-TFS.
Nie wiem czemu Microsoft zdecydował się na taki krok. SVN nie działa dobrze, nie wspiera wielu komend i praktycznie nie jest rozwijamy co świadczy o tym, że jest to swego rodzaju ślepa uliczka, w którą zabrnięto i wycofano się. Wycofano się do Mercurial wspieranego natywnie.
Czemu nie zdecydowano się na natywnego SVN, którym na pewno było by mniej roboty, może Microsoft liczył, że nastąpi migracja na TFS, chciał go w jakiś sposób zareklamować.
I tak oto mam repozytorium w ichnim SVN i nie ma jak danych wyciągnąć. svnsync, svn dump, svnrdump nie są wspierane.
Prośba o konwersję z SVN do Mercurial-a spotkała się z odmową, bo przykro nam bardzo, ale pana repozytorium należy do tych 5% których skonwertować nasze skrypty nie są w stanie.
Komenda hg sync jest wolna, przez całą noc nie była w stanie pobrać jednej z rewizji. I na pewno nie było tam więcej niż 50MB. Nie wiem po czyjej stronie leży błąd. hg sync albo ich SVN-ie.
Na szczęście jest jeszcze jedno rozwiązanie, tytułowe rozszerzenie do Mercurial.
Klonujemy repozytorium rozszerzenia:
W TortoiseHG odnajdujemy plik z konfiguracyjny z rozszerzeniami. Najprościej klikamy prawym w jakiś folder, w podmenu HG szukamy Settings. W oknie wybieramy Extensions, klikamy w ręczną edycję i dodajemy nowe rozszerzenie do listy, wskazujące na folder hgsubversion\hgsubversion. Zapisujemy plik.
Testujemy, że nasze rozszerzenie działa:
Teraz tylko pobieramy nasze repozytorium SVN do lokalnego repozytorium HG. Cały poces konwersji jest o niebo szybszy niż w przypadku hg sync. Może Microsoft powinien skorzystać z tego narzędzia by poradzić sobie z przypadkami trudnymi.
Skrypt który dokonuje konwersji:
No i porażka, większość rewizji jest pustych, następne do sprawdzenia: repozytorium SVN, analiza loga zatwierdzeń, pobranie wszystkich rewizji z loga, update po rewizjach, kopiowanie plików do repozytorium HG z kasowaniem w nim plików, zatwierdzenie HG z właściwym komentarzem, użytkownikiem i datą.
Jak to nie zadziała, to zakładam trzecie nowe repozytorium HG. Nie na CodePlex.
Nie wiem czemu Microsoft zdecydował się na taki krok. SVN nie działa dobrze, nie wspiera wielu komend i praktycznie nie jest rozwijamy co świadczy o tym, że jest to swego rodzaju ślepa uliczka, w którą zabrnięto i wycofano się. Wycofano się do Mercurial wspieranego natywnie.
Czemu nie zdecydowano się na natywnego SVN, którym na pewno było by mniej roboty, może Microsoft liczył, że nastąpi migracja na TFS, chciał go w jakiś sposób zareklamować.
I tak oto mam repozytorium w ichnim SVN i nie ma jak danych wyciągnąć. svnsync, svn dump, svnrdump nie są wspierane.
Prośba o konwersję z SVN do Mercurial-a spotkała się z odmową, bo przykro nam bardzo, ale pana repozytorium należy do tych 5% których skonwertować nasze skrypty nie są w stanie.
Komenda hg sync jest wolna, przez całą noc nie była w stanie pobrać jednej z rewizji. I na pewno nie było tam więcej niż 50MB. Nie wiem po czyjej stronie leży błąd. hg sync albo ich SVN-ie.
Na szczęście jest jeszcze jedno rozwiązanie, tytułowe rozszerzenie do Mercurial.
Klonujemy repozytorium rozszerzenia:
hg clone http://bitbucket.org/durin42/hgsubversion hgsubversion
W TortoiseHG odnajdujemy plik z konfiguracyjny z rozszerzeniami. Najprościej klikamy prawym w jakiś folder, w podmenu HG szukamy Settings. W oknie wybieramy Extensions, klikamy w ręczną edycję i dodajemy nowe rozszerzenie do listy, wskazujące na folder hgsubversion\hgsubversion. Zapisujemy plik.
Testujemy, że nasze rozszerzenie działa:
hg help hgsubversion
Teraz tylko pobieramy nasze repozytorium SVN do lokalnego repozytorium HG. Cały poces konwersji jest o niebo szybszy niż w przypadku hg sync. Może Microsoft powinien skorzystać z tego narzędzia by poradzić sobie z przypadkami trudnymi.
Skrypt który dokonuje konwersji:
set REP_DIR=winuae-codeplex-hg if exist %REP_DIR% goto CREATED hg init %REP_DIR% :CREATED cd %REP_DIR% :RECOVER hg recover :LOOP hg pull https://winuaeunofficial.svn.codeplex.com/svn echo errorlevel %ERRORLEVEL% if not %ERRORLEVEL% == 0 goto RECOVER :FINAL echo FINISHED pause
No i porażka, większość rewizji jest pustych, następne do sprawdzenia: repozytorium SVN, analiza loga zatwierdzeń, pobranie wszystkich rewizji z loga, update po rewizjach, kopiowanie plików do repozytorium HG z kasowaniem w nim plików, zatwierdzenie HG z właściwym komentarzem, użytkownikiem i datą.
Jak to nie zadziała, to zakładam trzecie nowe repozytorium HG. Nie na CodePlex.
2012-04-05
Generacja BLEP
Po ustaleniu, że nie filtrujemy naszego sygnału w dziedzinie częstotliwości ani czasu, tylko wykorzystujemy odpowiedzi na skok pozostaje nam ustalić jakie odpowiedzi na skok potrzebujemy.
Po pierwsze mamy nasze oryginalne BLEPy z WinUAE. Mamy BLEPy WinUAE generowane przez oryginalny skrypt. Są one takie same jak generowane przez skrypt w
Orygialne BLEPy nie wykorzystały większości funkcji z pakietu scipy:
Najważniejsze było dla mnie potwierdzenie, że generowane przeze mnie BLEPy są takie same w jak WinUAE. Ponieważ BLEPy WinUAE różnią zarówno od tych generowanych przez oryginalny skrypt jak i od generowanych przez mnie (wszystkie 3 grupy różnią się od siebie tak naprawdę). Napisałem więc prosty kod, które zadaniem było znalezienie takich stałych czasowych filtrów dla których moje wykresy wyglądałyby jak te w Pythonie. Stałe te są ujęte pod nazwami
Dzięki temu metodą z wykorzystaniem
W stosunku do WinUAE postanowiłem jeszcze wyprodukować wersję NTSC BLEPów, różnica jest niewielka, ale zawsze. Oczywiście można zapisać tylko jedną wersję i odpowiednio skalować i może nawet interpolować by pobrać prawidłową wartość dla NTSC. Na razie zapisuje di XMLa obie wersje, jak będzie później to się okaże.
Druga sprawa to dokładność BLEPa. W WinUAE jest to 16 bitów. U mnie na razie liczba zmiennoprzecinkowa.
Trzecie sprawa to dithering. Czy musimy go zastosować ?
Impuls służący do generacji naszego BLEPa jest potraktowany filtrem dolnoprzepustowym o częstotliwości 21KHz. Dzięki czemu próbkowanie wyjścia dźwięku z częstotliwością 44KHz powinno wywołać niewielki aliasing. Autor skryptu w Pythonie twierdzi, że powinien się też nadać do próbkowania z 48KHz. Teoretycznie jest to prawda. Na pewno nie nadaję się on do próbkowania z niższymi częstotliwościami, a takie wspierał WinUAE. Osobiście wydaje mi się, że współcześnie będę obsługiwał tylko jeden tryb 44KHz.
Częstotliwość 21KHz została wybrana zamiast 22KHz gdyż dla tej drugiej wyższe częstotliwości nie były zbyt dobrze tłumione.
Na większość tych pytań będę musiał odpowiedzieć kiedy wygeneruje WAVE z próbek wyjść Pauli ( kanał, wartość, cykl). I zrobię jakąś analizę spektralną. Dla porównania mam jedną melodię, do której posiadam także plik MOD, którą ktoś nagrał w 4 podstawowych konfiguracjach filtrów (A1200/A500, LED on/off).
No i ostatnia kwestia - wpływ starzenia się na elementy filtrów. Innymi słowy jaki był wiek Amig z których mam zgrane sygnały i czy ma on znaczenie.
Na razie mam wygenerowane BLEPy dla wszystkich parametrów filtrów zgodnie z posiadanymi schematami elektrycznymi. Oraz tak dobrane parametry by odtwarzać przebiegi z jakich korzysta WinUAE.
Po pierwsze mamy nasze oryginalne BLEPy z WinUAE. Mamy BLEPy WinUAE generowane przez oryginalny skrypt. Są one takie same jak generowane przez skrypt w
genblep. Wygenerowane przez nasz BLEPy różnią się od tych oryginalnych z WinUAE. Czemu nie wiem. Orygialne BLEPy nie wykorzystały większości funkcji z pakietu scipy:
lsim, tworzenie filtrów. Wszystko zostało napisane ręcznie. Najważniejsze było dla mnie potwierdzenie, że generowane przeze mnie BLEPy są takie same w jak WinUAE. Ponieważ BLEPy WinUAE różnią zarówno od tych generowanych przez oryginalny skrypt jak i od generowanych przez mnie (wszystkie 3 grupy różnią się od siebie tak naprawdę). Napisałem więc prosty kod, które zadaniem było znalezienie takich stałych czasowych filtrów dla których moje wykresy wyglądałyby jak te w Pythonie. Stałe te są ujęte pod nazwami
A500 WinUAE i A1200 WinUAE. Dzięki temu metodą z wykorzystaniem
lsim jestem w stanie wygenerować zarówno moje BLEPy jak te oryginalne z WinUAE. W stosunku do WinUAE postanowiłem jeszcze wyprodukować wersję NTSC BLEPów, różnica jest niewielka, ale zawsze. Oczywiście można zapisać tylko jedną wersję i odpowiednio skalować i może nawet interpolować by pobrać prawidłową wartość dla NTSC. Na razie zapisuje di XMLa obie wersje, jak będzie później to się okaże.
Druga sprawa to dokładność BLEPa. W WinUAE jest to 16 bitów. U mnie na razie liczba zmiennoprzecinkowa.
Trzecie sprawa to dithering. Czy musimy go zastosować ?
Impuls służący do generacji naszego BLEPa jest potraktowany filtrem dolnoprzepustowym o częstotliwości 21KHz. Dzięki czemu próbkowanie wyjścia dźwięku z częstotliwością 44KHz powinno wywołać niewielki aliasing. Autor skryptu w Pythonie twierdzi, że powinien się też nadać do próbkowania z 48KHz. Teoretycznie jest to prawda. Na pewno nie nadaję się on do próbkowania z niższymi częstotliwościami, a takie wspierał WinUAE. Osobiście wydaje mi się, że współcześnie będę obsługiwał tylko jeden tryb 44KHz.
Częstotliwość 21KHz została wybrana zamiast 22KHz gdyż dla tej drugiej wyższe częstotliwości nie były zbyt dobrze tłumione.
Na większość tych pytań będę musiał odpowiedzieć kiedy wygeneruje WAVE z próbek wyjść Pauli ( kanał, wartość, cykl). I zrobię jakąś analizę spektralną. Dla porównania mam jedną melodię, do której posiadam także plik MOD, którą ktoś nagrał w 4 podstawowych konfiguracjach filtrów (A1200/A500, LED on/off).
No i ostatnia kwestia - wpływ starzenia się na elementy filtrów. Innymi słowy jaki był wiek Amig z których mam zgrane sygnały i czy ma on znaczenie.
Na razie mam wygenerowane BLEPy dla wszystkich parametrów filtrów zgodnie z posiadanymi schematami elektrycznymi. Oraz tak dobrane parametry by odtwarzać przebiegi z jakich korzysta WinUAE.
2012-04-03
Kompilacja UADE pod Cygwin
Krok pierwszy to instalacja Cygwin. Wraz Z GCC4, Make, Install, Sed. Po pierwszej instalacji odpalamy instalację jeszcze raz i dorzucamy pkg-config.
Pobieramy źródła UADE, wypakowujemy je, uruchamiamy Cygwin. Montujemy katalog ze źródłami:
Okazuje się, że nie mam dostępnego polecenia
Uruchamiamy:
Dowiemy się, że nie zostaną zainstalowane jakieś pluginy dla Linuxowych playerów - nieważne. Co ważniejsze nie mamy GCC C. Znowu instalator i doinstalowujemy GCC4 C Core.
Uruchamiamy:
Tak na marginesie wygląda na to, że instalator całkiem sprawnie sobie radzi przy włączonej konsoli Cygwin.
Uruchamiamy:
Teraz
Przy okazji warto się zapoznać z plikiem
Teraz jeszcze dopieszczamy wszystko. Robimy by cała skompilowana zawartość lądowała w katalogu
Wywołujemy:
Teraz czas tak dostosować proces by z poziomu Windows dało się uruchomić nasz UADE. W sumie musiałem skopiować trzy biblioteki dll z katalogu Cygwin.
Teraz musimy sobie poradzić z systemem plików. Odnajdujemy plik
Ostatecznie poradziłem sobie z tym modyfikując główny
Modyfikując
I modyfikując plik
Podane zmiany są kasowane przez polecenie
Pobieramy źródła UADE, wypakowujemy je, uruchamiamy Cygwin. Montujemy katalog ze źródłami:
mount -f "D:\Programowanie\C++\Moje programy\winuae\docs\audio\uade 2.13" /srcOkazuje się, że nie mam dostępnego polecenia
Make, uruchamiamy instalator i doinstalowujemy Make.Uruchamiamy:
./configureDowiemy się, że nie zostaną zainstalowane jakieś pluginy dla Linuxowych playerów - nieważne. Co ważniejsze nie mamy GCC C. Znowu instalator i doinstalowujemy GCC4 C Core.
Uruchamiamy:
./configure. Tym razem brakuje libao. Doinstalowujemy. Tak na marginesie wygląda na to, że instalator całkiem sprawnie sobie radzi przy włączonej konsoli Cygwin.
Uruchamiamy:
./configure. Bez błędów. Teraz
make. I make soundcheck.Przy okazji warto się zapoznać z plikiem
INSTALL.readme.Teraz jeszcze dopieszczamy wszystko. Robimy by cała skompilowana zawartość lądowała w katalogu
/src/bin/. Wywołujemy:
make clean
./configure --prefix=/src/bin
make
make soundcheck
make installTeraz czas tak dostosować proces by z poziomu Windows dało się uruchomić nasz UADE. W sumie musiałem skopiować trzy biblioteki dll z katalogu Cygwin.
Teraz musimy sobie poradzić z systemem plików. Odnajdujemy plik
uadeconfig.h i modyfikujemy ścieżki na względne tak jak poustawiało nam pliki ostatnie polecenie make install.Ostatecznie poradziłem sobie z tym modyfikując główny
Makefile:BINDIR = /src/bin
DATADIR = /src/bin/share/uade2
DOCDIR = {DOCDIR}
MANDIR = /src/bin/share/man/man1
LIBDIR = /src/bin/lib/uade2Modyfikując
src\frontends\uade123\Makefile:BINDIR = /src/binI modyfikując plik
uadeconfig.h:#define UADE_CONFIG_BASE_DIR "share/uade2"
#define UADE_CONFIG_UADE_CORE "lib/uade2/uadecore.exe"Podane zmiany są kasowane przez polecenie
./configure.
hg convert svn
Przykładowy plik cmd którego zadaniem jest zreplikowanie zawartości repozytorium SVN do Mercurial.
Operacje można w dowolnym momencie przerwać i wznowić. Cały proces jest odporny na różnego rodzaju błędy jakie mogą się pojawić po drodze (a przy dużych repozytoriach zawsze coś może nawalić np. z połączeniem sieciowym).
Operacje można w dowolnym momencie przerwać i wznowić. Cały proces jest odporny na różnego rodzaju błędy jakie mogą się pojawić po drodze (a przy dużych repozytoriach zawsze coś może nawalić np. z połączeniem sieciowym).
set REP_DIR=winuae-codeplex :RECOVER if not exist %REP_DIR% goto LOOP cd winuae-codeplex hg recover cd .. :LOOP hg convert https://winuaeunofficial.svn.codeplex.com/svn %REP_DIR% echo errorlevel %ERRORLEVEL% if not %ERRORLEVEL% == 0 goto RECOVER :FINAL echo FINISHED pause
svnsync
Polecenia tego użyjemy do wykonania kopii zdalnego repozytorium do lokalnego katalogu. Wszystko pod systemem Windows.
Do wykonania operacji musimy mieć dostęp z wiersza poleceń do podstawowych poleceń SVN.
Tworzymy lokalne repozytorium:
W pliku
Wykonujemy inicjalizację synchronizacji:
I otrzymujemy informację o błędzie:
Tworzymy pusty plik
Ponawiamy polecenie. Teraz powinno być wszystko w porządku.
Teraz czas na właściwą synchronizację:
Kiedy przerwiemy proces synchronizacji, repozytorium może zostać pozostawione w stanie zablokowania. Musimy usunąć z niego pozostawioną właściwość:
Kompletny skrypt wznawiający synchronizację w pętli aż do skutku:
Do wykonania operacji musimy mieć dostęp z wiersza poleceń do podstawowych poleceń SVN.
Tworzymy lokalne repozytorium:
svnadmin create winuae-google-svnW pliku
svnserve.conf ustawiamy dostęp anonimowy do zapisu i odczytu.anon-access = read
auth-access = writeWykonujemy inicjalizację synchronizacji:
svnsync init "file:///D:/Programowanie/C++/winuae-google-svn" https://winuae-mod.googlecode.com/svn/I otrzymujemy informację o błędzie:
svnsync: E165006: Repozytorium nie ma włączonej możliwości zmieniania atrybutów wersji;
poproś administratora o utworzenie skryptu hook pre-revprop-changeTworzymy pusty plik
winuae-google-svn\hooks\pre-revprop-change.batPonawiamy polecenie. Teraz powinno być wszystko w porządku.
Teraz czas na właściwą synchronizację:
svnsync sync "file:///D:/Programowanie/C++/winuae-google-svn" https://winuae-mod.googlecode.com/svn/Kiedy przerwiemy proces synchronizacji, repozytorium może zostać pozostawione w stanie zablokowania. Musimy usunąć z niego pozostawioną właściwość:
svn pdel --revprop -r 0 svn:sync-lock "file:///D:/Programowanie/C++/winuae-google-svn"Kompletny skrypt wznawiający synchronizację w pętli aż do skutku:
goto RECOVER
:LOOP
svnsync sync "file:///D:/Programowanie/C++/Moje programy/winuae-google-svn" https://winuae-mod.googlecode.com/svn/
echo errorlevel %ERRORLEVEL%
if not %ERRORLEVEL% == 0 goto RECOVER
goto FINAL
:RECOVER
svn pdel --revprop -r 0 svn:sync-lock "file:///D:/Programowanie/C++/Moje programy/winuae-google-svn"
goto LOOP
:FINAL
echo FINISHED
pause
:LOOP
svnsync sync "file:///D:/Programowanie/C++/Moje programy/winuae-google-svn" https://winuae-mod.googlecode.com/svn/
echo errorlevel %ERRORLEVEL%
if not %ERRORLEVEL% == 0 goto RECOVER
goto FINAL
:RECOVER
svn pdel --revprop -r 0 svn:sync-lock "file:///D:/Programowanie/C++/Moje programy/winuae-google-svn"
goto LOOP
:FINAL
echo FINISHED
pause
2012-04-02
Rekonstrukcja sygnału wyjściowego na podstawie odpowiedzi na skok
Mamy funkcję odpowiedzi na skok. Każda zmian na na wyjściu ADC generuje na wyjściu filtra odpowiedź na skok. Za każdym razem naszą funkcję odpowiedzi na skok musimy przeskalować by wartości skoku były sobie równe.
Nasz filtr posiada następujące właściwości. Jest liniowy. Czyli odpowiedź na sumę dwóch sygnałów wyjściowych jest sumą odpowiedzi na każdy z sygnałów wejściowych z osobna. Jest time-invariant. Odpowiedź na sygnał wejściowy zawsze następuje po takim samym czasie.
Dzięki temu możemy powiedzieć, że sygnał wyjściowy z naszego filtru, będący odpowiedzią na pewien zbiór skoków jednostkowych na wejściu jest złożeniem odpowiedzi na skok tego filtru na każdy wejściowy skok z osobna.
Ponieważ oscylację naszego skoku z czasem stabilizują się potrzebujemy pamiętać na tyle długo na ile się zmienia. WinUAE wykorzystuje długość skoku 2048 cykli i takiej długości mniej więcej musi być bufor time-ahead.
Przykładowe odpowiedzi na skok tak jak w WinUAE:

Do przeczytania polecam ten pdf: Hard Sync Without Aliasing.
Metoda ta nada się także do symulacji dźwięku w starszych systemach, np. w C64.
Metoda ta jest dużo szybsza od stosowania splotu.
Nasz filtr posiada następujące właściwości. Jest liniowy. Czyli odpowiedź na sumę dwóch sygnałów wyjściowych jest sumą odpowiedzi na każdy z sygnałów wejściowych z osobna. Jest time-invariant. Odpowiedź na sygnał wejściowy zawsze następuje po takim samym czasie.
Dzięki temu możemy powiedzieć, że sygnał wyjściowy z naszego filtru, będący odpowiedzią na pewien zbiór skoków jednostkowych na wejściu jest złożeniem odpowiedzi na skok tego filtru na każdy wejściowy skok z osobna.
Ponieważ oscylację naszego skoku z czasem stabilizują się potrzebujemy pamiętać na tyle długo na ile się zmienia. WinUAE wykorzystuje długość skoku 2048 cykli i takiej długości mniej więcej musi być bufor time-ahead.
Przykładowe odpowiedzi na skok tak jak w WinUAE:
Do przeczytania polecam ten pdf: Hard Sync Without Aliasing.
Metoda ta nada się także do symulacji dźwięku w starszych systemach, np. w C64.
Metoda ta jest dużo szybsza od stosowania splotu.
Odpowiedź na skok, a odpowiedź na impuls
Mając odpowiedź na impuls układu poszukujemy jego odpowiedzi na skok.
Splot impulsu z funkcją skoku po stronie czasu jest równoznaczny z mnożeniem po stronie częstotliwości, czyli w tym wypadku filtrowaniu.
$(f * g)(t) = \displaystyle\int_0^t f(\tau)g(t-\tau)\,d\tau$
Podstawiając za g(t) funkcję skoku otrzymujemy:
$\displaystyle\int_0^t f(\tau)\, d\tau$$
, gdzie f(t) to odpowiedź impulsowa filtra.
Przykład funkcji w matlabie do generacji odpowiedzi na skok, posiadając odpowiedź na impuls:
I funkcja odwrotna do powyższej:
Splot impulsu z funkcją skoku po stronie czasu jest równoznaczny z mnożeniem po stronie częstotliwości, czyli w tym wypadku filtrowaniu.
$(f * g)(t) = \displaystyle\int_0^t f(\tau)g(t-\tau)\,d\tau$
Podstawiając za g(t) funkcję skoku otrzymujemy:
$\displaystyle\int_0^t f(\tau)\, d\tau$$
, gdzie f(t) to odpowiedź impulsowa filtra.
Przykład funkcji w matlabie do generacji odpowiedzi na skok, posiadając odpowiedź na impuls:
function [ blep ] = step_calc( blip )
step = ones(1, size(blip, 2));
blep = conv(step, blip);
blep = blep(1:1:size(blip, 2));
blep = blep / blep(end);
endI funkcja odwrotna do powyższej:
function [ blip ] = destep_calc( blep )
blip = [blep, 0] - [0, blep];
blip = blip(1:1:end-1);
blip = blip / trapz(blip);
endJak we mgle
Mając podane rozwiązanie na patelni w postaci gotowego kodu w Pythonie, który to jest używany do generacji odpowiedzi na skok, które są używane do symulacji dźwięku w Amidze, Ja postanowiłem odkryć na nowo Amerykę. Główna przyczyna: nie rozumiałem tego kodu w Pythonie i wydawało mi się, że można to zrobić lepiej, bardziej elegancko.
Zacząłem od wygenerowania odpowiedzi impulsowej filtru. Z charakterystyki częstotliwościowej filtru otrzymanej z LTSpice, gdzie narysowałem schemat filtru i dokonałem symulacji pracy takiego układu. Bezpośrednio z równań funkcji przejścia, wyliczając ich transformaty odwrotne. Z funkcji MatLAB
Wszystkie te rozwiązania sprowadzały się do stworzenia odpowiedzi impulsowej filtru. W oparciu o nią pokazanie jak zachowuje się filtr przepuszczając przez niego impuls, którego widmo zawiera częstotliwości do 21KHz (prostokąt w domenie częstotliwości). Wyższych nie ma co analizować raz ze względu na częstotliwości odcięcia filtrów no i tego, że mamy do czynienia z dźwiękiem.
Splot tych dwóch impulsów daje nam wynik - odpowiedź impulsową naszego filtru na sygnał zawierający częstotliwości do 21KHz.
O tym dlaczego 21KHz powiem prawdopodobnie więcej później.
Taka odpowiedź impulsowa jest podstawą do dalszej zabawy.
Zanim się połapałem o co chodzi tak naprawdę w kodzie zawartym w Pythonie, z jakiś postów których kopie mam w dokumentacji myślałem, że bierzemy taką odpowiedź impulsową i splatamy ją z naszym sygnałem wyjściowym z Pauli otrzymując przefiltrowany sygnał wyjściowy.
I to pewnie by działało, ale jest wolniejsze od rozwiązania zastosowanego w WinUAE.
Zamiast odpowiedzi impulsowej generujemy odpowiedź na skok. I teraz każda zmiana sygnału wyjściowego z Pauli generuje odpowiedź na skok - z reguły coś w rodzaju gasnącej oscylacji. Sygnał wyjściowy jest superpozycją odpowiedzi na wszystkie skoki z osobna. Z uwagi na to, że sygnał odpowiedzi na skok szybko zanika w WinUAE analizie poddaje się tylko skoki z 2048 ostatnich cykli.
Poza tym wygenerowane przeze mnie impulsy wynikowe generowane są poprzez splot, co samo w sobie powoduje zniekształcenia (oba sygnały są skończone w czasie).
Zacząłem od wygenerowania odpowiedzi impulsowej filtru. Z charakterystyki częstotliwościowej filtru otrzymanej z LTSpice, gdzie narysowałem schemat filtru i dokonałem symulacji pracy takiego układu. Bezpośrednio z równań funkcji przejścia, wyliczając ich transformaty odwrotne. Z funkcji MatLAB
impulse. Z charakterystyki częstotliwościowej filtru wyliczonej z funkcji przejścia. Dla porównania miałem także wyniki skryptu w pythonie i tabel z WinUAE. No i jeszcze ostani sposób filtrowanie odbywa się w domenie częstotliwości i poprzez IFT generujemy impuls.Wszystkie te rozwiązania sprowadzały się do stworzenia odpowiedzi impulsowej filtru. W oparciu o nią pokazanie jak zachowuje się filtr przepuszczając przez niego impuls, którego widmo zawiera częstotliwości do 21KHz (prostokąt w domenie częstotliwości). Wyższych nie ma co analizować raz ze względu na częstotliwości odcięcia filtrów no i tego, że mamy do czynienia z dźwiękiem.
Splot tych dwóch impulsów daje nam wynik - odpowiedź impulsową naszego filtru na sygnał zawierający częstotliwości do 21KHz.
O tym dlaczego 21KHz powiem prawdopodobnie więcej później.
Taka odpowiedź impulsowa jest podstawą do dalszej zabawy.
Zanim się połapałem o co chodzi tak naprawdę w kodzie zawartym w Pythonie, z jakiś postów których kopie mam w dokumentacji myślałem, że bierzemy taką odpowiedź impulsową i splatamy ją z naszym sygnałem wyjściowym z Pauli otrzymując przefiltrowany sygnał wyjściowy.
I to pewnie by działało, ale jest wolniejsze od rozwiązania zastosowanego w WinUAE.
Zamiast odpowiedzi impulsowej generujemy odpowiedź na skok. I teraz każda zmiana sygnału wyjściowego z Pauli generuje odpowiedź na skok - z reguły coś w rodzaju gasnącej oscylacji. Sygnał wyjściowy jest superpozycją odpowiedzi na wszystkie skoki z osobna. Z uwagi na to, że sygnał odpowiedzi na skok szybko zanika w WinUAE analizie poddaje się tylko skoki z 2048 ostatnich cykli.
Poza tym wygenerowane przeze mnie impulsy wynikowe generowane są poprzez splot, co samo w sobie powoduje zniekształcenia (oba sygnały są skończone w czasie).
Filtr drugiego rzędu
Filtr dolnoprzepustowy aktywny drugiego rzędu w konfiguracji Sallen-Key:

Filtr ten jest włączany programowo. Wraz z filtrem pierwszego rzędu powoduje jeszcze silniejsze tłumienie sygnału.
Funkcja przejścia takiego filtru:
$H(s) = \displaystyle\frac{1}{s^2 R_1 R_2 C_1 C_2 + s(R_1 C_1 + R_2 C_2) + 1}$
Częstotliwość odcięcia:
$f_{CUT} = \displaystyle\frac{1}{2\pi\sqrt{R_1 R_2 C_1 C_2}}$
Dla filtru z A500 wynosi ona 3.1kHZ.
Zgodnie z tym co czytałem tranzystor odcinający ten filtr przepuszcza w stanie odcięcia niewielki prąd. Z uwagi na to, że jest to wartość stała powinna ona zostać odfiltrowana na kondensatorach filtrujących.
Filtr ten jest włączany programowo. Wraz z filtrem pierwszego rzędu powoduje jeszcze silniejsze tłumienie sygnału.
Funkcja przejścia takiego filtru:
$H(s) = \displaystyle\frac{1}{s^2 R_1 R_2 C_1 C_2 + s(R_1 C_1 + R_2 C_2) + 1}$
Częstotliwość odcięcia:
$f_{CUT} = \displaystyle\frac{1}{2\pi\sqrt{R_1 R_2 C_1 C_2}}$
Dla filtru z A500 wynosi ona 3.1kHZ.
Zgodnie z tym co czytałem tranzystor odcinający ten filtr przepuszcza w stanie odcięcia niewielki prąd. Z uwagi na to, że jest to wartość stała powinna ona zostać odfiltrowana na kondensatorach filtrujących.
Funkcja przejścia filtru pierwszego stopnia
Typowy schemat aktywnego filtru dolnoprzepustowego:
![]()
Filtr ten jest używany we wszystkich modelach Amigi. Nie da się go wyłączyć.
Funkcja przejścia ma postać:
$H(s) = \displaystyle\frac{1}{s R_2 C + 1}$
Częstotliwość odcięcia takiego filtru:
$f_{CUT} = \displaystyle\frac{1}{2 \pi R_2 C}$
Dla typowej A500 będzie to 4.4KHz.
Filtr ten jest używany we wszystkich modelach Amigi. Nie da się go wyłączyć.
Funkcja przejścia ma postać:
$H(s) = \displaystyle\frac{1}{s R_2 C + 1}$
Częstotliwość odcięcia takiego filtru:
$f_{CUT} = \displaystyle\frac{1}{2 \pi R_2 C}$
Dla typowej A500 będzie to 4.4KHz.
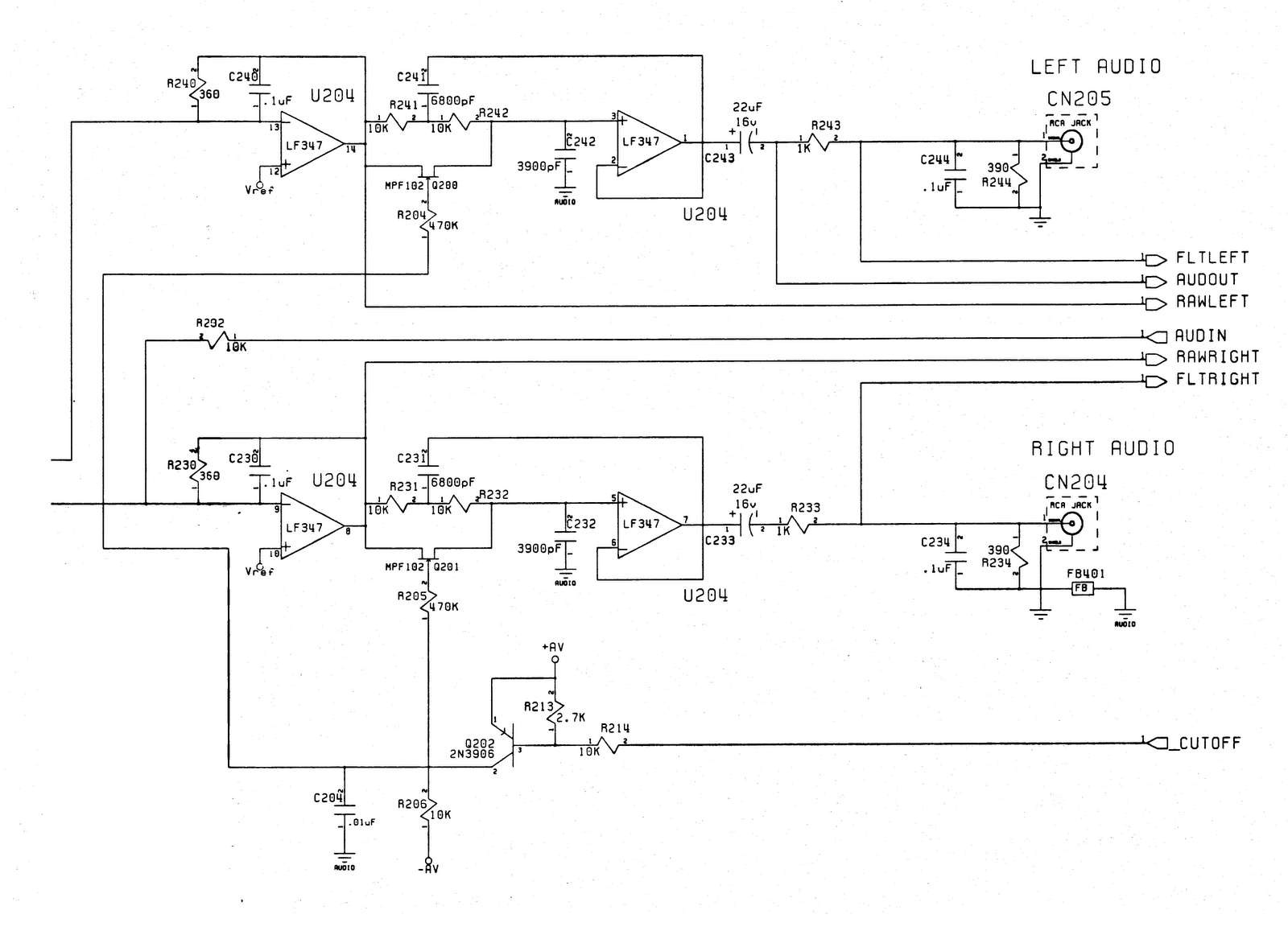
Filtr audio
Typowy filtr audio w Amidze - po jednym na każdy kanał składa się w połączonych kaskadowo dwóch filtrów dolnpoprzepustowych: filtru pierwszego rzędu i filtru drugiego rzędu w topologii Sallen–Key. Oba filtry są operarte na wzmacniaczu LF347. Filtr drugiego stopnia jest sterowany programomo. W niektórych modelach o statnie filtru informuje dioda LED zasilania, jeśli jest przygaszona to filtr ten jest wyłączony. Stanem filtru sterujemy poprzez jedno z wyjść układu CIA.
Typowy schemat, który nie zmienia się od A1000 do A4000:
Filtry dla różnych modeli Amig różnią tylko wartością elementów RC.

Z posiadanych przeze mnie schematów wynika, że CD32 nie była wyposażona w filtr drugiego stopnia. Zaś niektóry modele A1000 i A2000 były wyposażone w zupełnie inna konfigurację elementów RC, ale pewnie dające podobną charakterystykę filtru.
Zestawione w tabele wartości z różnych schematów prezentują się następująco:
Dwa puste rzędy to wspomniane wyżej modele A1000 i A2000 z inną topologią RC.
Co do dwóch ostatnich filtrów. Tutaj trochę wybiegnę w przyszłość. W sieci znalazłem dokument który zawiera kod w pythonie z wykorzystaniem SciPy, który generuje przebiegi odpowiedzi na skok tego filtru. W kodzie tym nie ma podanych parametrów RC wprost, są za to podane parametry funkcji przejścia. Z nich wyliczyłem teoretyczne parametry C zakładając, że parametry R są takie same. Co więcej zostały one odpracowane tak by filtr programowy dawał podobne efekty jak ten w Amidze.
Tutaj do uwzględnienia jest kolejna kwestia. Starzenie się elektroniki i jej wpływ na pracę filtrów. Na razie nie potrafię oszacować, czy i jak powinna się zmienić charakterystyka 5-letniego filtru.
Typowy schemat, który nie zmienia się od A1000 do A4000:
Filtry dla różnych modeli Amig różnią tylko wartością elementów RC.
Z posiadanych przeze mnie schematów wynika, że CD32 nie była wyposażona w filtr drugiego stopnia. Zaś niektóry modele A1000 i A2000 były wyposażone w zupełnie inna konfigurację elementów RC, ale pewnie dające podobną charakterystykę filtru.
Zestawione w tabele wartości z różnych schematów prezentują się następująco:
| Model | C331 | R331 | R332 | R333 | C332 | C333 |
| "A500 R6a7" | 100nF | 360 | 10k | 10k | 6.8nF | 3.9nF |
| "A500" | 100nF | 360 | 10k | 10k | 7.5nF | 3.9nF |
| "A500+" | 100nF | 360 | 10k | 10k | 6.8nF | 3.9nF |
| "A600" | 100nF | 360 | 10k | 10k | 6.8nF | 3.9nF |
| "A1000" | ||||||
| "A1200" | 6.8nF | 680 | 10k | 10k | 6.8nF | 3.9nF |
| "A1200 #2" | 3.9nF | 1500 | 10k | 10k | 6.8nF | 3.9nF |
| "A2000 #1" | 100nF | 360 | 10k | 10k | 6.8nF | 3.9nF |
| "A2000 #2" | 47nF | 750 | 10k | 10k | 6.8nF | 3.9nF |
| "A2000 #3" | ||||||
| "A3000" | 100nF | 360 | 10k | 10k | 6.8nF | 3.9nF |
| "CD32" | 6.8nF | 330 | 10k | 10k | 6.8nF | 3.9nF |
| "CDTV" | 47nF | 750 | 10k | 10k | 6.8nF | 3.9nF |
| "A4000" | 47nF | 750 | 10k | 10k | 6.8nF | 3.9nF |
| "A500 winuae" | 90nF | 360 | 10k | 10k | 6.3nF | 3.7nF |
| "A1200 winuae" | 7.3nF | 680 | 10k | 10k | 6.3nF | 3.7nF |
Co do dwóch ostatnich filtrów. Tutaj trochę wybiegnę w przyszłość. W sieci znalazłem dokument który zawiera kod w pythonie z wykorzystaniem SciPy, który generuje przebiegi odpowiedzi na skok tego filtru. W kodzie tym nie ma podanych parametrów RC wprost, są za to podane parametry funkcji przejścia. Z nich wyliczyłem teoretyczne parametry C zakładając, że parametry R są takie same. Co więcej zostały one odpracowane tak by filtr programowy dawał podobne efekty jak ten w Amidze.
Tutaj do uwzględnienia jest kolejna kwestia. Starzenie się elektroniki i jej wpływ na pracę filtrów. Na razie nie potrafię oszacować, czy i jak powinna się zmienić charakterystyka 5-letniego filtru.
Generacja dźwięku - wstęp
Za generację dźwięku w Amidze, odpowiedzialny jest układ Paula. Układ ten posiada dwa analogowe wyjścia audio - kanał lewy i prawy. Rozdzielczość ADC to 8-bitów.
Dodatkowo istnieją jakieś tryby kiedy jeden kanał moduluje częstotliwość lub/i amplitudę drugiego. W takim trybie możliwe jest uzyskanie sygnału o 14-bitowej rozdzielczości. Na pewno jest to bardzo rzadko wykorzystywane, nie jestem pewny czy WinUAE to nawet emuluje. Gry z tego nie korzystają, ewentualnie jakieś programy muzyczne. Na razie tymi trybami się nie przejmuje.
Paula wewnętrznie posiada 4 kanały, po dwa na każdy kanał stereo.
Amiga to komputer, którego działanie silnie zależy od zegara taktującego. Cały proces generacji obrazu, dźwięku odbywa się w takt zegara. Ponieważ obraz generowany jest w PAL i NTSC dla obu systemów mamy inne zegary taktujące, odpowiednio $FREQ_{PAL} = 7093790$, $FREQ_{NTSC} = 7159090$. Stąd wynika maksymalna częstotliwość sygnału jaką Paula jest w stanie wygenerować: połowa powyższego.
Z uwagi na czas w jakim powstała Amiga zastosowanie DSP nie było możliwe. Mimo to Amiga radzi sobie z generacją zdigitalizowanego dźwięku, ale odbywa się to kosztem jakości.
Paula generuje sygnał o maksymalnej częstotliwości około 3.5 MHz, który jest filtrowany i wzmacniany.
Paula w każdej linii pobiera 4 16-bitowe słowa, czyli po dwie próbki na każdy z 4 kanałów. Ponieważ moment uzyskania dostępu do pamięci w linii ekranu nie jest ustalony Paula posiada bufor 2x4 bajty. Kiedy 4 próbki są odtwarzane, 4 kolejne mogą zostać załadowane.
Częstotliwości wyświetlania obrazu są następujące:
$FPS_{PAL} = 50$
$FPS_{NTSC} = 59.94$
Liczba linii ma klatkę w obu systemach:
$LINES_{PAL} = 625/ 2$
$LINES_{NTSC} = 525/2$
525 i 625 to liczba linii w przeplocie czyli na dwie klatki.
Stąd możemy policzyć ile maksymalnie próbek na sekundę w obu systemach jest w stanie pobrać i wygenerować Paula:
$SAMPLESMAX_{PAL} = 2 * LINES_{PAL} * FPS_{PAL} = 31250$
$SAMPLESMAX_{NTSC} = 2 * LINES_{NTSC} * FPS_{NTSC} = 31468.5$
2 to liczba próbek na kanał jakie maksymalnie może Paula pobrać z pamięci podczas jednej linii.
Tutaj trochę mi mieszają. Zgodnie z dokumentacją liczba próbek została ograniczona do $SAMPLESMAX = 28867$.
Tak więc teraz możemy policzyć co ile minimalnie cykli może się zmienić odtwarzana próbka by zachować to kryterium:
$CYCLESPERSAMPLE_{PAL} = FREQ_{PAL} / SAMPLESMAX / 2 = 123$
$CYCLESPERSAMPLE_{NTSC} = FREQ_{NTSC} / SAMPLESMAX / 2 = 124$
2 gdyż, częstotliwość procesora to jedno, a cykle to drugie. CPU posiada 16-bitową magistralę danych, zaś operuje na słowach 32-bitowych, czyli dostęp do każdej danej zajmuje mu dwa cykle zegarowe.
Paula posiada rejestr 16-bitowy definiujący przez ile cykli może być utrzymywana próbka na wyjściu. Jeśli wartość jest mniejsza od minimalnej nie ma gwarancji, że następna próbka zostanie uzyskana na czas. Odtwarzana jest wtedy próbka poprzednia.
Z pewnością jest tutaj jeszcze wiele problemów do rozwiązania. Skąd te 28867. Choć liczba linii w PAL to 625 maksymalna rozdzielczość to 400 linii. Reszta linii tworzy ramkę. Co się konkretnie dzieje jak nie mamy następnej próbki, a następną trzeba odtworzyć, co się dzieje jak właściwa próbka nadejdzie, czy następuje jakaś desynchronizacja.
Z drugiej strony możemy policzyć minimalną częstotliwość z jaką może być odtwarzany dźwięk. Zakładamy, że w rejestr jest wpisana wartość 63355.
$SAMPLESMIN_{PAL} = FREQ_{PAL} / 65535 / 2 = 54$
$SAMPLESMIN_{NTSC} = FREQ_{NTSC} / 65535 / 2 = 55$
Wartości te to ilość próbek generowanych na sekundę. Taka liczba próbek pozwala odtworzyć sinusoidę o częstotliwości 27 i 27.5. Z drugiej strony maksymalna częstotliwość to 14.4Khz. Człowiek jest w stanie usłyszeć dźwięki od około 20 do 20000Hz. 14.4KHz to ciągle jest dużo, gdyż 200000 to bardziej wartość teoretyczna.
Generowanie jednokanałowego dźwięku z maksymalną częstotliwością wymaga strumienia danych rzędu 28KB na kanał.
Przypuśćmy, że mamy zarejestrowaną próbkę jakiegoś instrumentu z tą częstotliwością. I chcemy ją odegrać na niższym tonie. Odtwarzamy więc ją wolniej wpisując do rejestru wartość większą niż 124. Konkretna wysokość tonu zależy od częstotliwości z jaką dźwięk został zarejestrowany.
Normalnie współcześnie melodia, efekty dźwiękowe są przygotowane w postaci strumienia WAV (MP3). Na Amidze z uwagi na wielkość pamięci maszyn z tamtych czasów nie było technicznie możliwe by odtwarzać muzykę jako WAV.
Próbki instrumentów były rejestrowane każdy z osobna, a następnie odtwarzane z wybraną częstotliwością na 4 kanałach (4 głosowa polifonia).
W tamtych czasach nie było praktycznie możliwe użycie DSP to konwersji częstotliwościowej próbki. Było to zbyt drogie. CPU był o wiele za wolny na tą operację. Taka konwersja, czyli resampling, to proces podczas którego zmieniamy częstotliwość sygnału i jednocześnie filtrujemy dolno-przepustowo sygnał by wyeliminować zjawisko aliasingu. Z braku takiego układu dźwięk generowany jest zniekształcony.
Częściowo można temu zaradzić przygotowując więcej niż jedną próbkę o kilku pośrednich częstotliwościach. Prawdopodobnie było to rzadko używane w grach, ale częściej przy odtwarzaniu modułu.
Rozwiązaniem problemu było filtrowanie sygnału. Każdy kanał z osobna. Filtr taki składał się z kaskadowo połączonych dwóch filtrów, jeden z nich włączony na stałe, drugi włączany programowo. Filtry te i ich parametry zostaną omówione później.
Z uwagi na to, że filtr włączony na stałe ma częstotliwość odcięcia 4.4KHz, generalnie nie jesteśmy w stanie usłyszeć niczego powyżej 7KHz. Z tego powoduje próbki powinny być rejestrowane z częstotliwością wyższą niż 14KHz. Czyli pomimo tego, że teoretycznie maksymalna częstotliwość jaką jesteśmy w stanie wygenerować to 14KHz, filtr ucina wszystko co jest powyżej 7KHz. Związku z tym (za dokumentacją) dla próbkowania większego niż 320 (4KHz) cykli zaczynamy gubić generowane wyższe częstotliwości.
Ich zadaniem jest eliminacja aliasingu, który charakteryzuje się w przypadku dźwięku z Amigi zakłóceniami na wysokich częstotliwościach.
Każdy z czterech kanałów jest wyposażony w 6 bitową regulację głośności.
Mimo wszystko było to prawdopodobnie wszystko co najlepsze co dało się uzyskać w tamtych czasach.
Dodatkowo istnieją jakieś tryby kiedy jeden kanał moduluje częstotliwość lub/i amplitudę drugiego. W takim trybie możliwe jest uzyskanie sygnału o 14-bitowej rozdzielczości. Na pewno jest to bardzo rzadko wykorzystywane, nie jestem pewny czy WinUAE to nawet emuluje. Gry z tego nie korzystają, ewentualnie jakieś programy muzyczne. Na razie tymi trybami się nie przejmuje.
Paula wewnętrznie posiada 4 kanały, po dwa na każdy kanał stereo.
Amiga to komputer, którego działanie silnie zależy od zegara taktującego. Cały proces generacji obrazu, dźwięku odbywa się w takt zegara. Ponieważ obraz generowany jest w PAL i NTSC dla obu systemów mamy inne zegary taktujące, odpowiednio $FREQ_{PAL} = 7093790$, $FREQ_{NTSC} = 7159090$. Stąd wynika maksymalna częstotliwość sygnału jaką Paula jest w stanie wygenerować: połowa powyższego.
Z uwagi na czas w jakim powstała Amiga zastosowanie DSP nie było możliwe. Mimo to Amiga radzi sobie z generacją zdigitalizowanego dźwięku, ale odbywa się to kosztem jakości.
Paula generuje sygnał o maksymalnej częstotliwości około 3.5 MHz, który jest filtrowany i wzmacniany.
Paula w każdej linii pobiera 4 16-bitowe słowa, czyli po dwie próbki na każdy z 4 kanałów. Ponieważ moment uzyskania dostępu do pamięci w linii ekranu nie jest ustalony Paula posiada bufor 2x4 bajty. Kiedy 4 próbki są odtwarzane, 4 kolejne mogą zostać załadowane.
Częstotliwości wyświetlania obrazu są następujące:
$FPS_{PAL} = 50$
$FPS_{NTSC} = 59.94$
Liczba linii ma klatkę w obu systemach:
$LINES_{PAL} = 625/ 2$
$LINES_{NTSC} = 525/2$
525 i 625 to liczba linii w przeplocie czyli na dwie klatki.
Stąd możemy policzyć ile maksymalnie próbek na sekundę w obu systemach jest w stanie pobrać i wygenerować Paula:
$SAMPLESMAX_{PAL} = 2 * LINES_{PAL} * FPS_{PAL} = 31250$
$SAMPLESMAX_{NTSC} = 2 * LINES_{NTSC} * FPS_{NTSC} = 31468.5$
2 to liczba próbek na kanał jakie maksymalnie może Paula pobrać z pamięci podczas jednej linii.
Tutaj trochę mi mieszają. Zgodnie z dokumentacją liczba próbek została ograniczona do $SAMPLESMAX = 28867$.
Tak więc teraz możemy policzyć co ile minimalnie cykli może się zmienić odtwarzana próbka by zachować to kryterium:
$CYCLESPERSAMPLE_{PAL} = FREQ_{PAL} / SAMPLESMAX / 2 = 123$
$CYCLESPERSAMPLE_{NTSC} = FREQ_{NTSC} / SAMPLESMAX / 2 = 124$
2 gdyż, częstotliwość procesora to jedno, a cykle to drugie. CPU posiada 16-bitową magistralę danych, zaś operuje na słowach 32-bitowych, czyli dostęp do każdej danej zajmuje mu dwa cykle zegarowe.
Paula posiada rejestr 16-bitowy definiujący przez ile cykli może być utrzymywana próbka na wyjściu. Jeśli wartość jest mniejsza od minimalnej nie ma gwarancji, że następna próbka zostanie uzyskana na czas. Odtwarzana jest wtedy próbka poprzednia.
Z pewnością jest tutaj jeszcze wiele problemów do rozwiązania. Skąd te 28867. Choć liczba linii w PAL to 625 maksymalna rozdzielczość to 400 linii. Reszta linii tworzy ramkę. Co się konkretnie dzieje jak nie mamy następnej próbki, a następną trzeba odtworzyć, co się dzieje jak właściwa próbka nadejdzie, czy następuje jakaś desynchronizacja.
Z drugiej strony możemy policzyć minimalną częstotliwość z jaką może być odtwarzany dźwięk. Zakładamy, że w rejestr jest wpisana wartość 63355.
$SAMPLESMIN_{PAL} = FREQ_{PAL} / 65535 / 2 = 54$
$SAMPLESMIN_{NTSC} = FREQ_{NTSC} / 65535 / 2 = 55$
Wartości te to ilość próbek generowanych na sekundę. Taka liczba próbek pozwala odtworzyć sinusoidę o częstotliwości 27 i 27.5. Z drugiej strony maksymalna częstotliwość to 14.4Khz. Człowiek jest w stanie usłyszeć dźwięki od około 20 do 20000Hz. 14.4KHz to ciągle jest dużo, gdyż 200000 to bardziej wartość teoretyczna.
Generowanie jednokanałowego dźwięku z maksymalną częstotliwością wymaga strumienia danych rzędu 28KB na kanał.
Przypuśćmy, że mamy zarejestrowaną próbkę jakiegoś instrumentu z tą częstotliwością. I chcemy ją odegrać na niższym tonie. Odtwarzamy więc ją wolniej wpisując do rejestru wartość większą niż 124. Konkretna wysokość tonu zależy od częstotliwości z jaką dźwięk został zarejestrowany.
Normalnie współcześnie melodia, efekty dźwiękowe są przygotowane w postaci strumienia WAV (MP3). Na Amidze z uwagi na wielkość pamięci maszyn z tamtych czasów nie było technicznie możliwe by odtwarzać muzykę jako WAV.
Próbki instrumentów były rejestrowane każdy z osobna, a następnie odtwarzane z wybraną częstotliwością na 4 kanałach (4 głosowa polifonia).
W tamtych czasach nie było praktycznie możliwe użycie DSP to konwersji częstotliwościowej próbki. Było to zbyt drogie. CPU był o wiele za wolny na tą operację. Taka konwersja, czyli resampling, to proces podczas którego zmieniamy częstotliwość sygnału i jednocześnie filtrujemy dolno-przepustowo sygnał by wyeliminować zjawisko aliasingu. Z braku takiego układu dźwięk generowany jest zniekształcony.
Częściowo można temu zaradzić przygotowując więcej niż jedną próbkę o kilku pośrednich częstotliwościach. Prawdopodobnie było to rzadko używane w grach, ale częściej przy odtwarzaniu modułu.
Rozwiązaniem problemu było filtrowanie sygnału. Każdy kanał z osobna. Filtr taki składał się z kaskadowo połączonych dwóch filtrów, jeden z nich włączony na stałe, drugi włączany programowo. Filtry te i ich parametry zostaną omówione później.
Z uwagi na to, że filtr włączony na stałe ma częstotliwość odcięcia 4.4KHz, generalnie nie jesteśmy w stanie usłyszeć niczego powyżej 7KHz. Z tego powoduje próbki powinny być rejestrowane z częstotliwością wyższą niż 14KHz. Czyli pomimo tego, że teoretycznie maksymalna częstotliwość jaką jesteśmy w stanie wygenerować to 14KHz, filtr ucina wszystko co jest powyżej 7KHz. Związku z tym (za dokumentacją) dla próbkowania większego niż 320 (4KHz) cykli zaczynamy gubić generowane wyższe częstotliwości.
Ich zadaniem jest eliminacja aliasingu, który charakteryzuje się w przypadku dźwięku z Amigi zakłóceniami na wysokich częstotliwościach.
Każdy z czterech kanałów jest wyposażony w 6 bitową regulację głośności.
Mimo wszystko było to prawdopodobnie wszystko co najlepsze co dało się uzyskać w tamtych czasach.
2012-03-26
Winforms - bugi
Tutaj dobre źródło informacji o błędzie: http://social.msdn.microsoft.com/Forums/ar/winformsdesigner/thread/6f56b963-df4d-4f26-8dc3-0244d129f07c
Post jest z 2006 roku. Mamy 2012 i błąd ciągle jest. Jestem prawie pewien, że został zgłoszony nie raz.
W skrócie chodzi o to, że jeśli umieścimy sobie ToolStrip na TabPage to ten ToolStrip sobie potrafi losowo zniknąć. U mnie najczęściej kiedy kliknę w jakiś przycisk i przeskakuje do kodu.
Rozwiązanie tymczasowe to włączenie wszystkich ToolStrip-ów na starcie aplikacji. Inaczej ryzykujemy z dużym prawdopodobieństwem wypuszczenie aplikacji z pewnymi brakami.
I nie jest to jedyny antyczny bug. Z pamięci ostatnio napotkane mam jeszcze dwa.
Pierwszy związany z serializacją do XML. Jeśli nasza klasa
Tutaj jest opis tego błędu: http://connect.microsoft.com/VisualStudio/feedback/details/97762/serializing-types-that-implement-ienumerable-t-causes-error-cs0136. Z roku 2006.
Kolejny to mruganie ListBox-a. Tutaj użyłem jakiegoś kodu z 2008 roku, by to połatać.
Czasami chciałbym żeby Microsoft po prostu połatał swoje produkty, wydał jakąś wersję typu breaking changes i pousuwał bugi, dokonał jakiegoś większego refaktoringu. Np. na szeroką skalę skorzystał z klas generycznych.
2012-04-25:
kolejny bug, kiedy nasz ListBox ma ustawiony IntegralHeight na false i jego wysokość jest taka, że ostatni item wyświetla się w połowie, to jeśli wybierzemy ostatni item do zaznaczenia, scroll ustawi się tak, że będzie on widoczny tylko w połowie.
kolejny bug, prawie nie możliwe jest odtworzenie programowe zaznaczanie, tak by ponowne kliknięcie z shiftem wybrało nowy prawidłowy obszar. Innymi słowy jeśli zaznaczymy od A do B z shiftem, odbudujemy programowo takie zaznaczenie to kiedy naciśniemy na C z shiftem to dostaniemy zaznaczenie od B do C. Pod warunkiem, że indeks C jest większy od indeksy B.
Post jest z 2006 roku. Mamy 2012 i błąd ciągle jest. Jestem prawie pewien, że został zgłoszony nie raz.
W skrócie chodzi o to, że jeśli umieścimy sobie ToolStrip na TabPage to ten ToolStrip sobie potrafi losowo zniknąć. U mnie najczęściej kiedy kliknę w jakiś przycisk i przeskakuje do kodu.
Rozwiązanie tymczasowe to włączenie wszystkich ToolStrip-ów na starcie aplikacji. Inaczej ryzykujemy z dużym prawdopodobieństwem wypuszczenie aplikacji z pewnymi brakami.
I nie jest to jedyny antyczny bug. Z pamięci ostatnio napotkane mam jeszcze dwa.
Pierwszy związany z serializacją do XML. Jeśli nasza klasa
A implementuje interfejs IEnumerable<B>, zaś B implementuje interfejs IEnumerable<C>, zaś C to zwykły obiekt to serializacja obiektu A spowoduje błąd. Generator kodu serializującego zagnieżdża kod w kodzie, w tym wypadku w kodzie serializacji klasy A zagnieżdżany jest kod serializacji klasy B, tylko, że nikt nie wpadł na pomysł zmiany nazw lokalnych zmiennych. I otrzymujemy naprawdę dziwny komunikat o błędzie.Tutaj jest opis tego błędu: http://connect.microsoft.com/VisualStudio/feedback/details/97762/serializing-types-that-implement-ienumerable-t-causes-error-cs0136. Z roku 2006.
Kolejny to mruganie ListBox-a. Tutaj użyłem jakiegoś kodu z 2008 roku, by to połatać.
Czasami chciałbym żeby Microsoft po prostu połatał swoje produkty, wydał jakąś wersję typu breaking changes i pousuwał bugi, dokonał jakiegoś większego refaktoringu. Np. na szeroką skalę skorzystał z klas generycznych.
2012-04-25:
kolejny bug, kiedy nasz ListBox ma ustawiony IntegralHeight na false i jego wysokość jest taka, że ostatni item wyświetla się w połowie, to jeśli wybierzemy ostatni item do zaznaczenia, scroll ustawi się tak, że będzie on widoczny tylko w połowie.
kolejny bug, prawie nie możliwe jest odtworzenie programowe zaznaczanie, tak by ponowne kliknięcie z shiftem wybrało nowy prawidłowy obszar. Innymi słowy jeśli zaznaczymy od A do B z shiftem, odbudujemy programowo takie zaznaczenie to kiedy naciśniemy na C z shiftem to dostaniemy zaznaczenie od B do C. Pod warunkiem, że indeks C jest większy od indeksy B.
2012-03-25
ToolStripButton.Image, ToolStripMenuItem.Image - skalowanie wysokiej jakości
Jeśli rozmiar ToolStripButton.Image jest większy niż ToolStrip.ImageScalingSize obrazek zostanie przeskalowany, będzie to jednak skalowanie niskiej jakości - najbliższy sąsiad. To samo dotyczy ToolStripMenuItem.Image.
Rozwiązania tego problemu są następujące:
Ja osobiście zdecydowałem się na trzecie rozwiązanie. Przygotowujemy sobie obrazki jako przeźroczyste PNG o rozmiarach 256x256 i skalujemy je do odpowiednich rozmiarów w razie potrzeby.
Wadą tego rozwiązania jest to, że nasz przeskalowany obrazek - 32x32 mniej, ale 16x16 już bardzo - to prawie pixel art - gdzie zręczny grafik dłubiąc ręcznie w pikselach jest w stanie uzyskać obrazek lepszej jakości niż przez przeskalowanie.
Kod jego implementacji:
Rozwiązania tego problemu są następujące:
- napisanie własnego menadżera rysowania (tego nie jestem pewny)
- przygotowanie obrazków we właściwych rozmiarach
- ich programowe przeskalowanie na starcie aplikacji
Ja osobiście zdecydowałem się na trzecie rozwiązanie. Przygotowujemy sobie obrazki jako przeźroczyste PNG o rozmiarach 256x256 i skalujemy je do odpowiednich rozmiarów w razie potrzeby.
Wadą tego rozwiązania jest to, że nasz przeskalowany obrazek - 32x32 mniej, ale 16x16 już bardzo - to prawie pixel art - gdzie zręczny grafik dłubiąc ręcznie w pikselach jest w stanie uzyskać obrazek lepszej jakości niż przez przeskalowanie.
Kod jego implementacji:
private void ResizeContextMenuStripImages()
{
foreach (var c in FindAll<Control>())
{
if (c.ContextMenuStrip == null)
continue;
foreach (var item in
c.ContextMenuStrip.Items.OfType<ToolStripMenuItem>())
{
if (item.Image == null)
continue;
var image = ResizeImage(
item.Image, c.ContextMenuStrip.ImageScalingSize);
item.Image.Dispose();
item.Image = image;
}
}
}
private void ResizeToolStripImages()
{
foreach (var toolstrip in FindAll<ToolStrip>())
{
foreach (var button in toolstrip.Items.OfType<ToolStripButton>())
{
if (button.Image == null)
continue;
var image = ResizeImage(button.Image, toolstrip.ImageScalingSize);
button.Image.Dispose();
button.Image = image;
}
}
}
private Bitmap ResizeImage(Image a_image, Size a_size)
{
Bitmap bmp = new Bitmap(a_size.Width, a_size.Height, a_image.PixelFormat);
using (Graphics g = Graphics.FromImage(bmp))
{
g.CompositingQuality = CompositingQuality.HighQuality;
g.InterpolationMode = InterpolationMode.HighQualityBicubic;
g.SmoothingMode = SmoothingMode.HighQuality;
g.DrawImage(a_image, 0, 0, bmp.Width, bmp.Height);
}
return bmp;
}
private IEnumerable<T> FindAll<T>(Control a_control = null)
{
List<T> list = new List<T>();
if (a_control == null)
a_control = this;
foreach (var c in a_control.Controls.OfType<T>())
list.Add(c);
foreach (var c in a_control.Controls.Cast<Control>())
list.AddRange(FindAll<T>(c));
return list;
}
2012-03-23
ListBox - zachowanie w MultiExtended
Mówimy tutaj o ListBox z WinForms w trybie zaznaczania MultiExtended.
Zaznaczmy jakiś element. Czyścimy listę, wypełniamy nowymi wartościami. Klikamy z shiftem w inny element i otrzymujemy zaznaczenie od "jednego bliżej" w stosunku do poprzednio klikniętego elementu do elementu klikniętego teraz.
Najpierw myślałem, że to jakiś bug, ale tak samo zachowuje się ListBox w MFC, czyli jest to raczej zachowanie Windowsa. Czystej kontrolki ListBox z API nie sprawdzałem - niech wspomnienia zostaną wspomnieniami. Tak więc nie jest to zachowanie WinForms.
Najdziwniejsze jest to, że chyba nic z tym nie da się zrobić. Informacja o poprzednim zaznaczeniu nie jest w żaden sposób dostępna i modyfikowalna. Z drugiej strony jakoś ten ListBox musi się zachować jak ktoś znienacka w niego kliknie z shiftem z zamiarem zaznaczenia. Dla mnie bardziej logiczne by było zaznaczanie tylko aktualnie wybranego elementu.
Zaznaczmy jakiś element. Czyścimy listę, wypełniamy nowymi wartościami. Klikamy z shiftem w inny element i otrzymujemy zaznaczenie od "jednego bliżej" w stosunku do poprzednio klikniętego elementu do elementu klikniętego teraz.
Najpierw myślałem, że to jakiś bug, ale tak samo zachowuje się ListBox w MFC, czyli jest to raczej zachowanie Windowsa. Czystej kontrolki ListBox z API nie sprawdzałem - niech wspomnienia zostaną wspomnieniami. Tak więc nie jest to zachowanie WinForms.
Najdziwniejsze jest to, że chyba nic z tym nie da się zrobić. Informacja o poprzednim zaznaczeniu nie jest w żaden sposób dostępna i modyfikowalna. Z drugiej strony jakoś ten ListBox musi się zachować jak ktoś znienacka w niego kliknie z shiftem z zamiarem zaznaczenia. Dla mnie bardziej logiczne by było zaznaczanie tylko aktualnie wybranego elementu.
2012-03-21
Naturalny porządek sortowania
Przez tytułowe hasło możemy rozumieć naprawdę wiele rzeczy. Ale problem głównie związany jest prawidłowym posortowaniem tekstu zawierającego liczby. Inaczej w naszym tekście ciągi liczb chcielibyśmy zastąpić jakby pojedynczym symbolem o wartości liczby. I tutaj możemy się zastanawiać jakie liczby jak wyodrębniać.
Głównym zadaniem sortowania jest radzenie sobie z prawidłowym sortowaniem string-ów z jakąś numeracją, kiedy te numery nie są uzupełniane zerami na początku (np. pliki).
Alternatywnie możemy skorzystać z gotowej metody, takiej samej jaką używa system do sortowania plików. Jest już napisana, przetestowana, użytkownik nie zostanie specjalnie zaskoczony działaniem sortowania innym od systemowego zwłaszcza jeśli idzie o nazwy plików. I być może przy okazji odpadają nam problemy z lokalizacją, które musielibyśmy uwzględnić pisząc taką metodę sami.
Sam kod jest bardzo prosty:
Głównym zadaniem sortowania jest radzenie sobie z prawidłowym sortowaniem string-ów z jakąś numeracją, kiedy te numery nie są uzupełniane zerami na początku (np. pliki).
Alternatywnie możemy skorzystać z gotowej metody, takiej samej jaką używa system do sortowania plików. Jest już napisana, przetestowana, użytkownik nie zostanie specjalnie zaskoczony działaniem sortowania innym od systemowego zwłaszcza jeśli idzie o nazwy plików. I być może przy okazji odpadają nam problemy z lokalizacją, które musielibyśmy uwzględnić pisząc taką metodę sami.
Sam kod jest bardzo prosty:
internal class NaturalOrderStringComparer : IComparer<string>
{
[DllImport("shlwapi.dll", CharSet = CharSet.Unicode, ExactSpelling = true)]
private static extern int StrCmpLogicalW(String a_x, String a_y);
public int Compare(string a_x, string a_y)
{
return StrCmpLogicalW(a_x, a_y);
}
}
Ikona w tray-u, a restart explorer-a
Explorer to dosyć niestabilny proces. Wchodzenie na 100% obciążenia, crash i restart zdarzają się od czasu do czasu. W takim wypadku ikonki naszych programów znikają z tray-a. Znikają ale programy działają dalej. Jeśli nasz program był zminimalizowany do tray-a to nie mamy go jak przywrócić. Można napisać aplikacje tak by uruchomienie drugiej instancji przywróciło pierwszą. Ale co jeśli dopuszczamy działanie wielu kopii aplikacji. Zawsze możemy oczywiście program zamknąć z menadżera zadań. Ale u mnie np. jest tych ikonek mnóstwo i jak się sypnie explorer to ich tak trochę ubywa. Naprawdę nie sposób się połapać co znikło do momentu aż jest to potrzebne.
Tak więc to czego potrzebujemy to automatyczne przywracanie ikony w tray-u po restarcie explorer-a. Korzystamy tutaj z message-a jaki explorer wyśle do nas w momencie utworzenia paska zadań. Wiadomość ta nie ma przypisanego kodu, explorer rejestruje ją za pomocą nazwy
Po pierwsze potrzebujemy eksportu do funkcji rejestrowania wiadomości:
Sama rejestracja:
I przechwytywanie wiadomości:
Tak więc to czego potrzebujemy to automatyczne przywracanie ikony w tray-u po restarcie explorer-a. Korzystamy tutaj z message-a jaki explorer wyśle do nas w momencie utworzenia paska zadań. Wiadomość ta nie ma przypisanego kodu, explorer rejestruje ją za pomocą nazwy
TaskbarCreated. Po pierwsze potrzebujemy eksportu do funkcji rejestrowania wiadomości:
[DllImport("user32.dll", SetLastError=true, CharSet=CharSet.Auto)]
private static extern uint RegisterWindowMessage(string a_name);Sama rejestracja:
private uint WM_TASKBARCREATED;
WM_TASKBARCREATED = RegisterWindowMessage("TaskbarCreated");I przechwytywanie wiadomości:
protected override void WndProc(ref Message a_msg)
{
if (a_msg.Msg == WM_TASKBARCREATED)
{
if (notifyIcon.Visible)
notifyIcon.Visible = true;
}
base.WndProc(ref a_msg);
}
2012-03-19
SequentialPartitioner
Poniższy
Narzut synchronizacji dla takiej metody jest dosyć duży. Nie jest ona także przyjazna dla pamięci cache. Zastosowanie takiej metody podziału to np. pobieranie plików z sieci:
Wywołanie
Partitioner zwraca elementy w kolejności w jakiej występują one w źródle enumeracji, niezależnie na ile wątków dane będą dzielone. Inaczej mówiąc enumeratory sub-podziałów zwracają elementy w kolejności jak w źródłowej kolekcji niezależnie od tego jak te elementy z sub-podziałów wyciągamy. Narzut synchronizacji dla takiej metody jest dosyć duży. Nie jest ona także przyjazna dla pamięci cache. Zastosowanie takiej metody podziału to np. pobieranie plików z sieci:
- przetwarzanie pojedynczego elementu jest długotrwałe
- wątek przez większość czasu jest zablokowany
- chcemy by elementy były pobierane w porządku występowania w kolekcji
GetDynamicPartitions() może być wywołany więcej niż jeden raz w trakcie życia SequentialPartitioner. Stąd w tej metodzie za każdym razem musimy tworzyć nasz nowy współdzielony enumerator. Umieszczenie go w obiekcie było by błędem. yield return nie umieszczamy w bloku lock gdyż wynik zostanie zwrócony podczas założonej blokady co w praktyce oznacza sekwencyjne przetwarzanie elementów kolekcji. Wywołanie
return GetDynamicPartitions(m_source.GetEnumerator()); jest konieczne. Jeśli enumerator będziemy tworzyć w głównej metodzie to za każdym wywołaniem metody (pobraniem enumeratora dla osobnego wątku) zostanie on utworzony na nowo. public class SequentialPartitioner<T> :
Partitioner<T>
{
private readonly IList<T> m_source;
public SequentialPartitioner(IList<T> a_source)
{
m_source = a_source;
}
public override bool SupportsDynamicPartitions
{
get
{
return true;
}
}
public override IList<IEnumerator<T>>
GetPartitions(int a_partition_count)
{
var dp = GetDynamicPartitions();
return (from i in Enumerable.Range(0, a_partition_count)
select dp.GetEnumerator()).ToList();
}
public override IEnumerable<T> GetDynamicPartitions()
{
return GetDynamicPartitions(m_source.GetEnumerator());
}
private static IEnumerable<T>
GetDynamicPartitions(IEnumerator<T> a_enumerator)
{
while (true)
{
T el;
lock (a_enumerator)
{
if (a_enumerator.MoveNext())
el = a_enumerator.Current;
else
yield break;
}
yield return el;
}
}
}
2012-02-17
GetFiles, GetDirectories, EnumerateDirectories, EnumerateFiles - UnauthorizedAccessException
Funkcje służąca do wyliczenia plików i katalogów w połączeniu z parametrem SearchOption.AllDirectories (a być może także bez niego) mają jedną wadę potrafią zwrócić wyjątek UnauthorizedAccessException, w przypadku katalogu do którego nie mamy praw. Najgorzej wygląda to właśnie podczas rekurencyjnego przeszukiwania całego drzewa. Jeśli gdzieś w tym drzewie jest plik/katalog do którego nie mamy praw to dostaniemy ten wyjątek.
Wydaje się, że powinno to zostać trochę bardziej elegancko rozwiązane. W praktyce oznacza to, że na podanych wyżej funkcjach nie można polegać. Bo taki katalog/plik może trafić się wszędzie.
Przy czym nie jestem pewien czy bardziej nie chodzi tutaj o katalogi niż o pliki. Tego nie sprawdzałem.
Moja wersja zwracająca wszystkie pliki w w drzewie katalogu i pomijająca te do których nie mamy praw:
Wydaje się, że powinno to zostać trochę bardziej elegancko rozwiązane. W praktyce oznacza to, że na podanych wyżej funkcjach nie można polegać. Bo taki katalog/plik może trafić się wszędzie.
Przy czym nie jestem pewien czy bardziej nie chodzi tutaj o katalogi niż o pliki. Tego nie sprawdzałem.
Moja wersja zwracająca wszystkie pliki w w drzewie katalogu i pomijająca te do których nie mamy praw:
public static void GetFiles(DirectoryInfo a_dir, List<string> a_files)
{
try
{
foreach (var file in a_dir.GetFiles())
a_files.Add(file.FullName);
}
catch
{
System.Console.WriteLine("dir ex: {0}", a_dir.FullName);
}
try
{
foreach (var dir in a_dir.GetDirectories())
GetFiles(dir, a_files);
}
catch (UnauthorizedAccessException)
{
System.Console.WriteLine("dir2 ex: {0}", a_dir.FullName);
}
}
2012-02-16
RestrictedFrequencyAction
Klasa jak sama nazwa wskazuje albo i nie służy do wywoływania delegatów z ograniczeniem: nie częściej niż pewien zadany czasy. Przydatna kiedy bardzo wiele wątków wprost bombarduje GUI żądaniami odświeżenia. W przypadku gdy pomiędzy kolejnymi akcjami nie upłynął określony czas aktualna akcja jest zapamiętywana jako kandydat do wywołania po upłynięciu czasu blokady. Należy pamiętać o tym, że z wszystkich akcji zablokowanych zostanie wywołana tylko ostania.
Nawet jeśli takie zjawisko w naszej aplikacji nie występuje, a może się zdarzyć, warto wykorzystać taką klasę by uniknąć problemów z czasem reakcji GUI.
Ja osobiście z tego modelu zrezygnowałem. Dlatego klasę utrwalam na blogu. Timer co 0.5s wystarcza w moim wypadku aż za nadto. Ponieważ wątki wykorzystują połączenia sieciowe real-time nie jest potrzebne.
Nawet jeśli takie zjawisko w naszej aplikacji nie występuje, a może się zdarzyć, warto wykorzystać taką klasę by uniknąć problemów z czasem reakcji GUI.
Ja osobiście z tego modelu zrezygnowałem. Dlatego klasę utrwalam na blogu. Timer co 0.5s wystarcza w moim wypadku aż za nadto. Ponieważ wątki wykorzystują połączenia sieciowe real-time nie jest potrzebne.
public class RestrictedFrequencyAction
{
private TimeSpan m_update_delta;
private DateTime LastPerform;
private volatile bool m_scheduled;
private Object m_lock = new Object();
private volatile Action m_action;
public RestrictedFrequencyAction(int a_update_delta_ms)
{
m_update_delta = new TimeSpan(0, 0, 0, 0, a_update_delta_ms);
LastPerform = DateTime.Now - m_update_delta - m_update_delta;
}
public void Perform(Action a_action)
{
lock (m_lock)
{
int t = (int)(m_update_delta -
(DateTime.Now - LastPerform)).TotalMilliseconds;
if (t < 0)
{
LastPerform = DateTime.Now;
a_action();
}
else
{
m_action = a_action;
if (!m_scheduled)
{
m_scheduled = true;
new Task(() =>
{
Thread.Sleep(t);
lock (m_lock)
{
LastPerform = DateTime.Now;
m_scheduled = false;
m_action();
}
}).Start();
}
}
}
}
}
RichTextBoxAppender
Jak w tytule, appender dla RichTextBox-a. W NLog dostępny w standardzie.
Powstał na podstawie wielu podobnych implementacji znalezionych w sieci.
Większość z nich używa
Czemu czegoś takiego nie ma w standardzie log4net, nie wiem. Wersja dla NLog oferuje znacznie więcej od tej tutaj (kolorowanie elementów linii loga, tworzenie osobnego okna z kontrolką, integracja z kontrolką na formatce z poziomu xml).
Powstał na podstawie wielu podobnych implementacji znalezionych w sieci.
Większość z nich używa
Invoke() do publikowani danych na kontrolce, co może prowadzić do deadlock-a, w sytuacji gdy wątek GUI i jakiś inny razem starają się coś zalogować. Zastąpienie Invoke() wersją asynchroniczną BeginInvoke rozwiązuje problem.Czemu czegoś takiego nie ma w standardzie log4net, nie wiem. Wersja dla NLog oferuje znacznie więcej od tej tutaj (kolorowanie elementów linii loga, tworzenie osobnego okna z kontrolką, integracja z kontrolką na formatce z poziomu xml).
public class RichTextBoxAppender : AppenderSkeleton
{
private RichTextBox m_rich_text_box = null;
private LevelMapping m_level_mapping = new LevelMapping();
public int MaxLines = 100000;
private delegate void UpdateControlDelegate(LoggingEvent a_logging_event);
public RichTextBoxAppender(RichTextBox a_rich_text_box)
: base()
{
m_rich_text_box = a_rich_text_box;
}
private void UpdateControl(LoggingEvent a_logging_event)
{
LevelTextStyle selectedStyle =
m_level_mapping.Lookup(a_logging_event.Level) as LevelTextStyle;
if (selectedStyle != null)
{
m_rich_text_box.SelectionBackColor = selectedStyle.BackColor;
m_rich_text_box.SelectionColor = selectedStyle.TextColor;
m_rich_text_box.SelectionFont =
new Font(m_rich_text_box.Font, selectedStyle.FontStyle);
}
m_rich_text_box.AppendText(RenderLoggingEvent(a_logging_event));
// Clear if too big.
if (MaxLines > 0)
{
if (m_rich_text_box.Lines.Length > MaxLines)
{
int pos = m_rich_text_box.GetFirstCharIndexFromLine(1);
m_rich_text_box.Select(0, pos);
m_rich_text_box.SelectedText = String.Empty;
}
}
// Autoscroll.
m_rich_text_box.Select(m_rich_text_box.TextLength, 0);
m_rich_text_box.ScrollToCaret();
}
protected override void Append(LoggingEvent a_logging_event)
{
if (m_rich_text_box.InvokeRequired)
{
m_rich_text_box.BeginInvoke(
new UpdateControlDelegate(UpdateControl),
new object[] { a_logging_event });
}
else
{
UpdateControl(a_logging_event);
}
}
public void AddMapping(LevelTextStyle a_mapping)
{
m_level_mapping.Add(a_mapping);
}
public override void ActivateOptions()
{
base.ActivateOptions();
m_level_mapping.ActivateOptions();
}
protected override bool RequiresLayout
{
get
{
return true;
}
}
}
public class LevelTextStyle : LevelMappingEntry
{
public bool Bold;
public bool Italic;
public Color TextColor;
public Color BackColor;
public FontStyle FontStyle { get; private set; }
public override void ActivateOptions()
{
base.ActivateOptions();
if (Bold)
FontStyle |= FontStyle.Bold;
if (Italic)
FontStyle |= FontStyle.Italic;
}
}
2012-02-14
Failed to load toolbox item 'controle name' it will be removed from the toolbox
Taki ostatnio napotkałem błąd. Tym samym nie możemy też bez dostania wyjątku otworzyć otworzyć formy z taką kontrolką jak i samej wizualizacji kontrolki.
Problem pojawił się kiedy do projektu dodałem DLL-ki korzystające z
Rozwiązanie polega na przerzuceniu kontrolek do assembly skofigurowanego na
Problem pojawił się kiedy do projektu dodałem DLL-ki korzystające z
mixed-mode i tym samym zmieniłem platformę z Any CPU na x64. Jak szukałem rozwiązania to tego nie wiedziałem, teraz jestem mądrzejszy po fakcie.Rozwiązanie polega na przerzuceniu kontrolek do assembly skofigurowanego na
Any CPU.
NHibernate - mapowanie
NHibernate możemy poinformować o sposobie w jaki powinien mapować obiekty na struktury bazy danych na kilka sposobów
Nasz obiekt nie jest w żaden sposób związany z klasami NHibernate.
Interfejs jest nam w tym przypadku potrzebny do automatyczneo namierzania klas:
1.
Mapowanie przez kod, w przypadku gdy nasze mapowanie jest rozdzielone od obiektów:public class Customer
{
public int Id { get; set; }
public string FirstName { get; set; }
}
public class CustomerMapping : ClassMapping<Customer>
{
public CustomerMapping()
{
Lazy(false);
Id<int>(x => x.Id, map => map.Generator(Generators.HighLow));
Property<string>(c => c.FirstName,
map => { map.Length(10); map.NotNullable(true); });
}
}
ModelMapper mapper = new ModelMapper();
mapper.AddMapping<CustomerMapping>();
HbmMapping mapping = mapper.CompileMappingFor(new[] { typeof(Customer) });Nasz obiekt nie jest w żaden sposób związany z klasami NHibernate.
2.
Mapowanie przez kod, w przypadku gdy nie chcemy tworzyć osobnych obiektów mapujących. public interface IClassMapping
{
void Map(ModelMapper a_mapper);
}
public class Customer : IClassMapping
{
public int Id { get; set; }
public string FirstName { get; set; }
public void Map(ModelMapper a_mapper)
{
a_mapper.Class<Customer>(m =>
{
m.Id(x => x.Id, map => map.Generator(Generators.HighLow));
m.Property(c => c.FirstName,
map => { map.Length(10); map.NotNullable(true); });
m.Lazy(false);
});
}
}Interfejs jest nam w tym przypadku potrzebny do automatyczneo namierzania klas:
private static void AddMappings()
{
ModelMapper mapper = new ModelMapper();
foreach (var asm in AssembliesToMap)
{
var types = from type in asm.GetTypes()
where !type.IsInterface
where type.IsImplementInterface(typeof(IClassMapping))
where !type.IsAbstract
select type;
foreach (var type in types)
(Activator.CreateInstance(type) as IClassMapping).Map(mapper);
}
HbmMapping mapping = mapper.CompileMappingForAllExplicitlyAddedEntities();
Configuration.AddDeserializedMapping(mapping, "MangaCrawler");
}3.
Mapowanie z wykorzystaniem atrybutów.4.
Mapowanie z wykorzystaniem XML.5.
Wykorzystanie zdarzeń klasy ModelMapper do dekorowania. Dzięki temu możemy jak mi się wydaje możemy obejść się dla większości elementów bez ręcznego mapowania. Np. możemy zdefiniować konwencję nazewnictwa kolumn w bazie, automatycznie podłączyć generatory id... Dokładnie tego nie sprawdzałem, być może jeszcze wiele innych rzeczy można ustandaryzować.
2012-02-11
NHibernate - metody czyszczenia bazy
1.
Jeśli tylko możemy możemy skasować plik, pliki bazy. Musimy mieć możliwość odtworzenia bazy. Po tej operacji należy jeszcze odtworzyć strukturę bazy.2.
FluentNHibernate.SessionSource.BuildSchema(Session) odtwarza strukturę bazy z ustawionego mapowania przy tym prawdopodobnie najpierw próbuje usunąć istniejące tabele.
3.
Buduje schemat bazy z mapowania, na podstawie niego usuwa z bazy tabele i je odtwarza.var export = new SchemaExport(cfg.BuildConfiguration());
export.Drop(false, true);
export.Create(false, true);4.
new SchemaExport(cfg).Execute(false, true, false); 5.
Chyba właściwe dla SQLite, z bazą łączymy się za pomocą: "db.db;New=True". Po tej operacji należy jeszcze odtworzyć strukturę bazy.Podsumowanie
2,3,4 robią dokładnie to samo. Najpierw tabele są usuwane, a następnie odtwarzane. 1,5 niszczą fizycznie bazę, która wymaga po takiej operacji odtworzenia struktury.
2012-02-10
SQLLite
Dla jednego z moich projektów: Manga Crawler postanowiłem podczas rozbudowy programu przejść na plikobazę SQLLite. Dostęp do niej zamierzam uzyskać poprzez jakiś ORM (prawdopodobnie NHibernate). Na razie chciałem uruchomić tylko dostęp poprzez ADO z wykorzystaniem System.Data.SQLite.
Jak zawsze staram się wszystko kompilować z źródeł. System.Data.SQLite jest pod tym względem wyjątkowo oporna. W solucji mamy trzy projekty:
SQLite.Interop.2010 - SQLLite + dodatkowy kod odpowiedzialny za rozszerzania, szyfrowanie, i zmienę zachowania pewnych funkcji z uwagi na GC w .NET. Wszystko jest kompilowane w C++.
System.Data.SQLite.2010 - źródła wrappera ADO w C#.
System.Data.SQLite.Module.2010 - dołączona jako moduł do pierwszego. Źródła takie same jak projekt 2. Zmieniane są tylko opcje kompilacji.
Z uwagi na to, że projekt 2 i 3 mają wspólne źródła ktoś wpadł na pomysł, że można części wspólne projektu powyłączać do osobnych plików i dołączać je. Nie jest to zły pomysł, tylko, że VS nie radzi sobie z tym i w explorerze nie ma żadnych plików.
Wszystkie 3 pliki projektów powinniśmy uważnie przestudiować gdyż mają one dużo niewidocznego z GUI kodu.
Moduł 3 dołączany do 1 to tak naprawdę skompilowane źródła (do języka pośredniego), moduły takie mogą się składać na assembly.
Jak to się dzieje, że nasz projekt 1 po dołączeniu 3 staje się assembly (w trybie mixed-mode, który powala na łączenie kodu niezarządzanego i zarządzanego). Cały projekt choć kompilowany jest zwykły projekt C++ ma poustawiane opcje tak, że w rzeczywistości jest mixed mode DLL.
W czym więc problem.
Jako referencje w naszym programie powinniśmy wskazać projekt 1, ale nie zawiera on zarządzanych źródeł z projektów 2 i 3. Tak więc nasze referencje w kodzie nie zostaną rozwiązane. Jeśli wskażemy projekt 2 to podczas uruchomienia dostaniemy błąd. Projekt drugi kompiluje się do System.Data.SQLite.2010.DLL, wykorzystuje natywne funkcje z SQLite.Interop.2010.DLL. Tak więc dostaniemy błąd o braku SQLite.Interop.2010.DLL. Kiedy kod z 2 jako 3 zostanie umieszczony w 1 żadnego błędu nie dostaniemy, wszystko jest w jednej bibliotece i kod zarządzany importuje symbole z niezarządzanej części tej samej DLLki.
Możemy oczywiście dodawać SQLite.Interop.2010.DLL do miejsca gdzie siedzi exe. Musimy to robić w post-build projektu. VS nie pozwala nam dodać referencję do niezarządanego projektu.
Teraz jak to pisze to przychodzi mi na myśl, że być może projekt 1 powinniśmy ustawić na zarządzalny, cały kod objąć klauzulą UNSAFE. Wtedy taki projekt moglibyśmy dodać do projektu z exe.
Jeśli projekt 2 skopiujemy tam gdzie exe w post-build to zawiera on powielony kod z 2. Nie wiem co się stanie jak załadujemy taką dllke, teoretycznie będziemy ją ładować jako niezarządzaną. Takie rozwiązanie wymaga trzech projektów w mojej solucji, których współdziałanie bez analizy będzie wywoływało wiele pytań. Po co 3, po co w dwóch to samo.
Osobiście zdecydowałem się na przerobienie projektów. Projekt 1 zawiera tylko źródła niezarządzalne i dodawany jest do głównego projektu w post-build. Do głównego projektu dodawany jest projekt 2. Nazwa dllki projektu 1 jest taka jakiej poszukuje projekt 2. Przy okazji powłączałem do plików projektów wszystkie includy.
Niby nic ale z uwagi na to jak to wszystko jest poplątane poszedł na to cały dzień. Osobiście nie jestem fanem takiego mieszania w pliku projektu, by mieszać nasz kod z kodem VS. Co najwyżej tu i tam dodać include do naszych elementów i tyle.
Całkiem przyjemną rzeczą byłaby możliwość ustawiania naszych opcji ustawianych w pliku projektu. Jak na razie jedyną możliwością ich zmiany są parametry podczas kompilacji z linii poleceń.
Przy okazji wywaliłem też jakieś bitmapy, zbędne jak mi się wydaje.
Zobaczymy czy będzie działać.
O ile podczas kolejnych wydań nie będą modyfikowane pliki projektów cała aktualizacja na nowy kod powinna przejść gładko.
Jak zawsze staram się wszystko kompilować z źródeł. System.Data.SQLite jest pod tym względem wyjątkowo oporna. W solucji mamy trzy projekty:
SQLite.Interop.2010 - SQLLite + dodatkowy kod odpowiedzialny za rozszerzania, szyfrowanie, i zmienę zachowania pewnych funkcji z uwagi na GC w .NET. Wszystko jest kompilowane w C++.
System.Data.SQLite.2010 - źródła wrappera ADO w C#.
System.Data.SQLite.Module.2010 - dołączona jako moduł do pierwszego. Źródła takie same jak projekt 2. Zmieniane są tylko opcje kompilacji.
Z uwagi na to, że projekt 2 i 3 mają wspólne źródła ktoś wpadł na pomysł, że można części wspólne projektu powyłączać do osobnych plików i dołączać je. Nie jest to zły pomysł, tylko, że VS nie radzi sobie z tym i w explorerze nie ma żadnych plików.
Wszystkie 3 pliki projektów powinniśmy uważnie przestudiować gdyż mają one dużo niewidocznego z GUI kodu.
Moduł 3 dołączany do 1 to tak naprawdę skompilowane źródła (do języka pośredniego), moduły takie mogą się składać na assembly.
Jak to się dzieje, że nasz projekt 1 po dołączeniu 3 staje się assembly (w trybie mixed-mode, który powala na łączenie kodu niezarządzanego i zarządzanego). Cały projekt choć kompilowany jest zwykły projekt C++ ma poustawiane opcje tak, że w rzeczywistości jest mixed mode DLL.
W czym więc problem.
Jako referencje w naszym programie powinniśmy wskazać projekt 1, ale nie zawiera on zarządzanych źródeł z projektów 2 i 3. Tak więc nasze referencje w kodzie nie zostaną rozwiązane. Jeśli wskażemy projekt 2 to podczas uruchomienia dostaniemy błąd. Projekt drugi kompiluje się do System.Data.SQLite.2010.DLL, wykorzystuje natywne funkcje z SQLite.Interop.2010.DLL. Tak więc dostaniemy błąd o braku SQLite.Interop.2010.DLL. Kiedy kod z 2 jako 3 zostanie umieszczony w 1 żadnego błędu nie dostaniemy, wszystko jest w jednej bibliotece i kod zarządzany importuje symbole z niezarządzanej części tej samej DLLki.
Możemy oczywiście dodawać SQLite.Interop.2010.DLL do miejsca gdzie siedzi exe. Musimy to robić w post-build projektu. VS nie pozwala nam dodać referencję do niezarządanego projektu.
Teraz jak to pisze to przychodzi mi na myśl, że być może projekt 1 powinniśmy ustawić na zarządzalny, cały kod objąć klauzulą UNSAFE. Wtedy taki projekt moglibyśmy dodać do projektu z exe.
Jeśli projekt 2 skopiujemy tam gdzie exe w post-build to zawiera on powielony kod z 2. Nie wiem co się stanie jak załadujemy taką dllke, teoretycznie będziemy ją ładować jako niezarządzaną. Takie rozwiązanie wymaga trzech projektów w mojej solucji, których współdziałanie bez analizy będzie wywoływało wiele pytań. Po co 3, po co w dwóch to samo.
Osobiście zdecydowałem się na przerobienie projektów. Projekt 1 zawiera tylko źródła niezarządzalne i dodawany jest do głównego projektu w post-build. Do głównego projektu dodawany jest projekt 2. Nazwa dllki projektu 1 jest taka jakiej poszukuje projekt 2. Przy okazji powłączałem do plików projektów wszystkie includy.
Niby nic ale z uwagi na to jak to wszystko jest poplątane poszedł na to cały dzień. Osobiście nie jestem fanem takiego mieszania w pliku projektu, by mieszać nasz kod z kodem VS. Co najwyżej tu i tam dodać include do naszych elementów i tyle.
Całkiem przyjemną rzeczą byłaby możliwość ustawiania naszych opcji ustawianych w pliku projektu. Jak na razie jedyną możliwością ich zmiany są parametry podczas kompilacji z linii poleceń.
Przy okazji wywaliłem też jakieś bitmapy, zbędne jak mi się wydaje.
Zobaczymy czy będzie działać.
O ile podczas kolejnych wydań nie będą modyfikowane pliki projektów cała aktualizacja na nowy kod powinna przejść gładko.
2012-02-02
How to center control in panel
This solution doesn't depend on any WinForms features like TableLayout, AutoScroll, Anchoring, etc. It requires panel with one control. It reacts on resizing of control and panel resizing. It doesn't change control size. When there is no sufficient place for control then scroll bar appears. Control left, top borders never go outside left, top borders of panel.
public static void CenterControlInPanel(Panel a_panel)
{
if (a_panel.Controls.Count != 1)
throw new InvalidOperationException();
Control control = a_panel.Controls[0];
a_panel.AutoScroll = false;
a_panel.AutoSize = false;
HScrollBar horz_bar = new HScrollBar();
VScrollBar vert_bar = new VScrollBar();
a_panel.Controls.Add(horz_bar);
a_panel.Controls.Add(vert_bar);
horz_bar.Dock = DockStyle.Bottom;
vert_bar.Dock = DockStyle.Right;
Panel panel = new Panel();
a_panel.Controls.Add(panel);
panel.Dock = DockStyle.Fill;
a_panel.Controls.Remove(control);
panel.Controls.Add(control);
Action on_scroll = () =>
{
if (panel.ClientSize.Width < control.Width)
{
if (horz_bar.Value > 0)
control.Left = -horz_bar.Value;
else
control.Left = 0;
}
else
control.Left = (panel.ClientSize.Width - control.Width) / 2;
if (panel.ClientSize.Height < control.Height)
{
if (vert_bar.Value > 0)
control.Top = -vert_bar.Value;
else
control.Top = 0;
}
else
control.Top = (panel.ClientSize.Height - control.Height) / 2;
};
Action on_resized = () =>
{
if (panel.ClientRectangle.Width < control.Width)
horz_bar.Visible = true;
else
horz_bar.Visible = false;
if (panel.ClientRectangle.Height < control.Height)
vert_bar.Visible = true;
else
vert_bar.Visible = false;
if (panel.ClientRectangle.Width < control.Width)
horz_bar.Visible = true;
else
horz_bar.Visible = false;
vert_bar.Minimum = 0;
vert_bar.Maximum = control.Height;
vert_bar.LargeChange = panel.ClientRectangle.Height;
horz_bar.Minimum = 0;
horz_bar.Maximum = control.Width;
horz_bar.LargeChange = panel.ClientRectangle.Width;
if (horz_bar.LargeChange + horz_bar.Value - 1 > control.Width)
horz_bar.Value = control.Width - horz_bar.LargeChange + 1;
if (vert_bar.LargeChange + vert_bar.Value - 1 > control.Height)
vert_bar.Value = control.Height - vert_bar.LargeChange + 1;
on_scroll();
};
panel.Resize += (s, e) => on_resized();
horz_bar.Scroll += (s, e) => on_scroll();
vert_bar.Scroll += (s, e) => on_scroll();
control.Resize += (s, e) => on_resized();
on_resized();
}
2012-02-01
Sekwencja Hammersley'a
Jest to pewna modyfikacja sekwencji Halton'a. Dla jednego z wymiarów sekwencja ma postać: $\displaystyle\frac{n-0.5}{N}$, gdzie n to numer kolejnej próbki. N to liczba próbek. Sekwencja ta ma mniejszą dyspersję niż sekwencja Haltona, za cenę określenia z góry ilości generowanych próbek.
-0.5 w wzorze zapewnia nam centrowanie punktów na środkach pikseli.
Sekwencja ta degraduje się dla wyższych wymiarów. W przypadku 2D bardzo szybko.
Przykłady:
2

3

4
 5
5

Widzimy, że być może i jest to sekwencja o niskiej dyspersji, ale punkty zdecydowanie układają się w wzór, który jak każda powtarzalność w próbkowaniu podatny jest na aliasing. Widać to też na poniższym periodogramie.
Przykład pierodogramu dla bazy 3:

Kod:
-0.5 w wzorze zapewnia nam centrowanie punktów na środkach pikseli.
Sekwencja ta degraduje się dla wyższych wymiarów. W przypadku 2D bardzo szybko.
Przykłady:
2
3
4
Widzimy, że być może i jest to sekwencja o niskiej dyspersji, ale punkty zdecydowanie układają się w wzór, który jak każda powtarzalność w próbkowaniu podatny jest na aliasing. Widać to też na poniższym periodogramie.
Przykład pierodogramu dla bazy 3:
Kod:
public static class LowDiscrepancyMath
{
public static double RadicalInverse(int a_n, int a_base)
{
double y = 0;
double b = a_base;
while (a_n > 0)
{
int d_i = a_n % a_base;
y += d_i / b;
a_n /= a_base;
b *= a_base;
}
return y;
}
}
public class HammersleySampler : LowDiscrepancySequenceSampler
{
private int m_n = 1;
private List<Vector2>[,] m_samples;
private int m_count;
public int BaseY = 3;
private double NextX()
{
return (m_n - 0.5) / m_count;
}
public override IEnumerable<Vector2> GetSamples(Rectangle a_rect)
{
foreach (var p in a_rect.EnumPixels())
{
if (m_samples[p.X, p.Y] == null)
continue;
foreach (var s in m_samples[p.X, p.Y])
yield return s;
}
}
public override SamplerType SamplerType
{
get
{
return SamplerType.Hammersley;
}
}
internal override void RenderStart(RenderStartPhase a_phase)
{
base.RenderStart(a_phase);
if (a_phase == RenderStartPhase.PrepareObjectToRender)
PrepareSamples();
}
private void PrepareSamples()
{
m_samples = new List<Vector2>[Film.Width, Film.Height];
m_count = Film.Width * Film.Height * Subresolution * Subresolution;
for (int i=0; i<m_count; i++)
{
Vector2 s = new Vector2(
NextX() * Film.Width,
LowDiscrepancyMath.RadicalInverse(m_n, BaseY) * Film.Height);
Point p = new Point((int)s.X, (int)s.Y);
if (m_samples[p.X, p.Y] == null)
m_samples[p.X, p.Y] = new List<Vector2>();
m_samples[p.X, p.Y].Add(s);
m_n++;
}
}
}
Subskrybuj:
Posty (Atom)