Za pomocą tego atrybutu kontrolujemy jak środowisko debugujące (Visual Studio) wyświetla nam informacje o stanie zmiennych (pól i właściwości) podczas debugowania. Reguły definiowane przez ten atrybut dotyczą zarówno okienek wyskakujących po najechaniu na zmienną, jak i tego co pojawia się w Watch, Autos, Locals. Atrybut ten może zostać nałożony na bardzo wiele elementów, poniżej wyciąg z źródeł:
[AttributeUsage(AttributeTargets.Assembly | AttributeTargets.Class | AttributeTargets.Struct | AttributeTargets.Enum | AttributeTargets.Property | AttributeTargets.Field | AttributeTargets.Delegate, AllowMultiple = true)] Klasa, struktura Rozpatrzmy najpierw użycie tego atrybuty na klasie (na strukturze wygląda identycznie):
class TestClass1
{
[System.Diagnostics.DebuggerBrowsable( System.Diagnostics. DebuggerBrowsableState.RootHidden)]
public int[] Collection
{
get
{
return new int[] { 1, 2, 3, 4 };
}
}
}Obiekt tej klasy w podglądzie będzie wyglądać następująco:

Jeśli klase tą oznaczymy atrybutem:
[System.Diagnostics.DebuggerDisplay("Count = {Collection.Length}")] , to jej wygląd w podglądzie zmieni się tak:

Jak widać w kolumnie
Value zamiast
{TestApp.Form1.TestClass1} pojawiła się informacja o ilości elementów. Jest to typowe zastosowanie tego atrybutu. Kolejny przykład:
[System.Diagnostics.DebuggerDisplay("Count = {Collection.Length}")] [System.Diagnostics.DebuggerDisplay("First = {Collection[0]}")] 
Jak widać choć kod się kompiluje, to efekt jest raczej błędny, pierwszy atrybut został zignorowany. W pierwszym przykładzie, kiedy klasa nie była opatrzona atrybutem, w kolumnie
Value wyświetliło się
{TestApp.Form1.TestClass1}. Informacja ta tak naprawdę podchodzi z funkcji
ToString(). Nadpisując tę funkcję możemy zmienić zawartość kolumny
Value bez używania atrybutów. Oczywiście nikt nie broni skorzystać nam z jednego i drugiego. Kolejny przykład:
[System.Diagnostics.
DebuggerDisplay("{ToString()}")]
class TestClass1
{
[System.Diagnostics.DebuggerBrowsable( System.Diagnostics. DebuggerBrowsableState.RootHidden)]
public int[] Collection
{
get
{
return new int[] { 1, 2, 3, 4 };
}
}
}
class TestClass2
{
[System.Diagnostics.DebuggerBrowsable( System.Diagnostics. DebuggerBrowsableState.RootHidden)]
public int[] Collection
{
get
{
return new int[] { 1, 2, 3, 4 };
}
}
}
O co chodzi z tym plusem ? Specyfikuje on nam klase wewnętrzną. Jeśli dla klasy
TestClass2 zdefiniujemy metodę:
public override string ToString()
{
return base.ToString();
}, to w obu stringach będzie plus. Nie wiem czemu ten plus tak się zachowuje.
Enum Rozpatrzmy taki przykład:
[System.Diagnostics.DebuggerDisplay("{this == TestEnum.Zatrzymany ? \"Off\" : \"On\"}")]
enum TestEnum
{
Zatrzymany,
Uruchomiony
}
class TestClass1
{
public static TestEnum enum1 = TestEnum.Uruchomiony;
public static TestEnum enum2 = TestEnum.Zatrzymany;
}
Jak widać w klamerkach {} może się znajdować dowolny kod. Szczerze dla
enum nie widzę sensownego zastosowania za wyjątkiem tłumaczenia nazw enumeracji na bardziej czytelne. Zobaczmy jak wygląda definicja enum w kodzie pośrednim:
[DebuggerDisplay("{this == TestEnum.Zatrzymany ? \"Off\" : \"On\"}")]
private enum TestEnum
{
Zatrzymany,
Uruchomiony
}Widzimy, że łańcuch znaków podany w klamerkach {} nie jest w żaden sposób kompilowany. Jak więc zachowa się debuger jak będziemy się starali debugować naszą klasę z poziomu np. VB. Generalnie jeśli VB, albo inny język nie rozpozna składni dostaniemy błąd. Najpewniejszym sposobem jest stworzenie specjalnej metody i wywoływanie jej z poziomu atrybutu. Takie rozwiązanie powinno zapewnić wysoką przenoszalność kodu. A najlepiej ograniczyć się tylko do napisania metody
ToString(). Przy okazji warto jeszcze wspomnieć, że możemy wpływać także na kolumnę
Type. Taki atrybut dla
enum:
[System.Diagnostics.DebuggerDisplay("{this == TestEnum.Zatrzymany ? \"Off\" : \"On\"}", Type = "Nie wiem")] Spowoduje zmianę w kolumnie
Type dla obu zmiennych klasy
TestClass1. Oczywiście typ można podmienić także dla innych elementów dla których możemy zaaplikować atrybut
DebuggerDisplayAttribute. Ja osobiście nie widzę powodu dla którego mielibyśmy modyfikować wartość tej kolumny.
Delegate Rozpatrzmy taki przykład:
class TestClass1
{
[System.Diagnostics.DebuggerDisplay("{ToString()}")]
public delegate void SimpleDelegateA();
public delegate void SimpleDelegateB();
public SimpleDelegateA simpleDelegateA1;
public SimpleDelegateA simpleDelegateA2;
public SimpleDelegateB simpleDelegateB1;
public SimpleDelegateB simpleDelegateB2;
public TestClass1()
{
simpleDelegateA1 = new SimpleDelegateA(TestFunc);
simpleDelegateB1 = new SimpleDelegateB(TestFunc);
}
public void TestFunc()
{
}
}
Z analizy tego przykładu możemy wyciągnąć wniosek, że na wszystkie delegaty został zaaplikowany atrybut w postaci
{Method = {Method}}. Powiem o tym w dalszej części postu. Przy okazji powiedzmy sobie pewną rzecz o klamerkach {}. Chcemy pokazać w debugerze takie coś:
{Method = {Void TestFunc()}}. Tak powinna wyglądać definicja atrybutu:
[System.Diagnostics.DebuggerDisplay(@"\{Methodx = {Method}\}")] [System.Diagnostics.DebuggerDisplay("\\{Methody = {Method}\\}")] [System.Diagnostics.DebuggerDisplay(@"\{Methodx = {Method}}")] [System.Diagnostics.DebuggerDisplay("\\{Methody = {Method}}")] Wszystkie 4 podejścia są poprawne. Ogólnie debuger bierze informację w klamerkach {} i stara się ją skompilować. Poprzedzając klamerkę \ mówimy debugerowi, że tak klamerka, to nie jest taka o, którą mu chodzi, ona należy do tekstowej części informacji. Klamerki kończącej nie musimy tutaj unieważniać gdyż pierwsza klamerka zamykająca, po otwierającej, jest tą o którą nam chodzi. Tutaj podaje mało sensowny przykład na potrzebę unieważnienia klamerki zamykającej:
[System.Diagnostics.DebuggerDisplay(@"\{Method = {Method + ""_\}_"" }}")] Pola, Właściwości Przykład:
class TestClass1
{
[System.Diagnostics.DebuggerDisplay("{Value}", Name = "{Key}")]
public class Pair
{
public int Key;
public string Value;
}
[System.Diagnostics.DebuggerBrowsable (System.Diagnostics. DebuggerBrowsableState.RootHidden)]
public Pair[] Collection
{
get
{
return new Pair[] { new Pair() { Key = 2, Value = "two" }, new Pair() { Key = 4, Value = "four" } };
}
}
}
Tutaj mamy przykład połączenia dwóch atrybutów
DebuggerDisplayAttribute i
DebuggerBrowsableAttribute.
Assembly Informacja tutaj podana odnosi się do VS2008. Wbrew pozorom nie nakładamy tego atrybutu na dowolny zestaw. Debuger nie uwzględni tej informacji. Przynajmniej tak wynikło z moich eksperymentów. W katalogu
Moje Dokumenty idziemy do
Visual Studio 2008\Visualizers. Interesują nas tam dwa pliki:
autoexp.cs i
autoexp.dll (polecam zrobić sobie ich kopię). Biblioteka to skompilowany plik źródłowy. Tworzymy nowy projekt biblioteki klas, usuwamy z projektu wszystkie pliki *.cs. Ddoajemy do projektu plik
autoexp.cs. Zmieniamy nazwę zestawu w opcjach projektu na
autoexp. Teraz możemy przystąpić do modyfikacji źródeł. Jako przykład dodajemy:
[assembly: DebuggerDisplay(@"\{Count = {Collection.Length}}", Target = typeof(TestApp.TestClass1))] Bardzo ważna uwaga. Jeśli naszym celem będzie klasa wewnętrzna nasze zmiany nie zadziałają. Kompilujemy i dodajemy utworzoną bibliotek do moich dokumentów. Restartujemy VS, i teraz jeśli użyjemy klasy
TestClass1 to debuger powinien uwzględnić nasze zmiany. Możemy także bez problemu zmodyfikować zawartość tego pliku jeśli coś w oryginalnej wizualizacji nam się nie podoba. Tutaj właśnie jest dodawany wpis, który modyfikuje sposób wyświetlania informacji o delegatach:
[assembly: DebuggerDisplay(@"\{Method = {Method}}", Target = typeof(System.Delegate))] Informacje uzupełniające Co jeśli podczas ewaluacji zmiennej do podglądu zdarzy się wyjątek ? 
Jak widać zostaniemy o tym poinformowani, nie przerwie to w żaden sposób obliczania zawartości pozostałych podglądanych elementów.
Jakim poziomem widzialności powinny się charakteryzować elementy z klamerkach {} ? public class TestClass2
{
private static int XX = 4;
}
[System.Diagnostics.DebuggerDisplay("{TestClass2.XX}")]
public class TestClass1
{
[System.Diagnostics.DebuggerDisplay("{System.DateTime.Now.dateData}")]
public int[] Collection
{
get
{
return new int[] { 1, 2, 3, 4 };
}
}
private int GetPrivate()
{
return 5555;
}
}
Taki kod będzie działał. Czyli odwołanie do prywatnych metod zarówno klasy w tej samej przestrzeni nazw, jak i w innej przestrzeni nazw (pola prywatnego klasy
DateTime będzie działać. Z jednej strony można to nazwać błędem. Z drugiej Watch powinien mieć dostęp do prywatnych składników klasy.
Czy w klamerkach mogą się znajdować wyrażenia oddzielone średnikami ? Nie, To co jest w klamerkach brane jest jako wyrażenie, które musi coś zwracać. Na potwierdzenie tego, jeśli wyrażenie w klamerkach nie zawiera średników i nic nie zwraca, otrzymujemy w Watch-u taki błąd:
Expression has been evaluated and has no value W przypadku, gdy wyrażenie zawiera średniki, debuger zachowuje się tak jakby atrybutu wogóle nie było.
Do czego tak naprawdę możemy się odwołać z wyrażenia w klamerkach {} ? Metody statyczne klas i metody obiektów, właściwości statyczne klas, właściwości obiektów, pola statyczne klas, pola obiektów, delegaty, zdarzenia. W samych klamerkach może być dowolny kod, który kompilator C# może skompilować. Prawie... Nie można używać wyrażeń lambda.
[System.Diagnostics.DebuggerDisplay("{Multiple(d => 2)}")]
public class TestClass1
{
public int Multiple(Func f)
{
return f(2) * 2;
}
}Dostaniemy błąd:
Expression cannot contain lambda expressions Modyfikator nq Rozpatrzmy taki przykład:
[System.Diagnostics.DebuggerDisplay("Name: {Name}, Age: {Age}")]
public class TestClass1
{
public String Name
{
get
{
return "name";
}
}
public int Age
{
get
{
return 56;
}
}
}
[System.Diagnostics.DebuggerDisplay("Name: {Name, nq}, Age: {Age}")]
public class TestClass2
{
public String Name
{
get
{
return "name";
}
}
public int Age
{
get
{
return 56;
}
}
}Debugger pokaże:

Jak widać za pomocą
nq możemy poinstruować debuger by wyrażenia, które są stringami, nie zamykać w cudzysłowach.
Problem z widocznością klas używanych w klamerkach {} Weźmy taki przykład:
[System.Diagnostics.DebuggerDisplay("{System.Int32.Parse(\"5\")}")]
public class TestClass1
{
}
[System.Diagnostics.DebuggerDisplay("{Int32.Parse(\"5\")}")]
public class TestClass2
{
}Debuger pokaże nam:

Widzimy, że używając dowolnej klasy spoza naszej przestrzeni nazw trzeba zawsze podać pełną nazwę klasy.
Czy atrybut Weźmy taki przykład:
[System.Diagnostics.DebuggerDisplay("{System.Int32.Parse(\"7\")}")]
public class TestClass1
{
[System.Diagnostics.DebuggerDisplay("{System.Int32.Parse(\"8\")}")]
public virtual int X
{
get
{
return 5;
}
}
}
[System.Diagnostics.DebuggerDisplay("{System.Int32.Parse(\"9\")}")]
public class TestClass2: TestClass1
{
public override int X
{
get
{
return 5;
}
}
}Takie coś zobaczymy podczas debugowania:

Gdyby klasa
TestClass2 była pozbawiona atrybutu to został by uwzględniony atrybut z klasy bazowej, tak jak to się dzieje z właściwością (to zachowanie zostało ustawione w atrybutach atrybutu
DebuggerDisplayAttribute). Widzimy, że możemy zobaczyć co generuje atrybut właściwości dla klasy
TestClass1 w widoku klasy bazowej, tego samego nie możemy powiedzieć o samej klasie. Poza tym warto zauważyć, jak można zafałszować to co pokazuje debuger na przykładzie właściwości X, gdzie możemy sprawić, że w kolumnie
Value może zostać pokazane zupełnie co innego.
 Po uzupełnieniu kodu odpowiednio:
Po uzupełnieniu kodu odpowiednio:  Dzięki użyciu tego atrybutu możemy kompleksowo zmienić sposób pokazywania zawartości klasy podczas debugowania. Co ważniejsze dane możemy wizualizować zupełnie inaczej niż wyglądają w strukturze obiektu. Jeśli obiekt implementuje strukturę listę (jak w powyższym przykładzie), możemy je pokazać jako tablicę, nie zmuszając użytkownika do klikania poprzez wszystkie elementy listy. Możemy zmienić wizualizację naszych klas, a także klas z biblioteki .NET (jak i dowolnie innej biblioteki). Możemy też powiedzieć, że atrybut ten pozwala nam rozdzielić kod dla debugera od kodu klasy. Jeśli klasa proxy musi się dostać do składników prywatnych klasy debugowanej najlepiej zdefiniować ją jako klasę wewnętrzną klasy debugowanej. Reszta informacji dla tego atrybutu podaje w postaci pytań i odpowiedzi. Jak można się przekonać niżej czasami coś nie działa, czasami działa inaczej niż powinno. Chyba wszystkie te sytuacje podane niżej kiedy coś nie działa, a powinno, można zakwalifikować jako błędy.
Dzięki użyciu tego atrybutu możemy kompleksowo zmienić sposób pokazywania zawartości klasy podczas debugowania. Co ważniejsze dane możemy wizualizować zupełnie inaczej niż wyglądają w strukturze obiektu. Jeśli obiekt implementuje strukturę listę (jak w powyższym przykładzie), możemy je pokazać jako tablicę, nie zmuszając użytkownika do klikania poprzez wszystkie elementy listy. Możemy zmienić wizualizację naszych klas, a także klas z biblioteki .NET (jak i dowolnie innej biblioteki). Możemy też powiedzieć, że atrybut ten pozwala nam rozdzielić kod dla debugera od kodu klasy. Jeśli klasa proxy musi się dostać do składników prywatnych klasy debugowanej najlepiej zdefiniować ją jako klasę wewnętrzną klasy debugowanej. Reszta informacji dla tego atrybutu podaje w postaci pytań i odpowiedzi. Jak można się przekonać niżej czasami coś nie działa, czasami działa inaczej niż powinno. Chyba wszystkie te sytuacje podane niżej kiedy coś nie działa, a powinno, można zakwalifikować jako błędy. 
 To ukrycie w śladzie wywołania dotyczy tylko debugera, ślad stosu uzyskany z wyjątku lub za pomocą
To ukrycie w śladzie wywołania dotyczy tylko debugera, ślad stosu uzyskany z wyjątku lub za pomocą  Tutaj, też widzimy zastosowanie tej opcji, polegające na ukrywaniu przed nami, wszelkich śladów wywołań, które nie dotyczą naszego kodu. Więcej informacji dostępnych jest
Tutaj, też widzimy zastosowanie tej opcji, polegające na ukrywaniu przed nami, wszelkich śladów wywołań, które nie dotyczą naszego kodu. Więcej informacji dostępnych jest 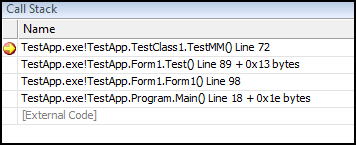 Atrybuty te powinniśmy stosować tylko dla dobrze przetestowanego kodu, by podczas debugowania nie szukać błędu i miejsca z błędem nie przeskakiwać. Można szybko docenić jego zalety implementując np. klasę liczby zespolonej, punktu, prostokąta, gdzie może być dużo małych upierdliwych metod, operatorów, konstruktorów wykonywanych setki razy.
Atrybuty te powinniśmy stosować tylko dla dobrze przetestowanego kodu, by podczas debugowania nie szukać błędu i miejsca z błędem nie przeskakiwać. Można szybko docenić jego zalety implementując np. klasę liczby zespolonej, punktu, prostokąta, gdzie może być dużo małych upierdliwych metod, operatorów, konstruktorów wykonywanych setki razy.
